
AI Agents in Production: Testing the Reasoning Loop
Part 3: Deterministic Testing with Trajectory Mocking

Agent testing breaks traditional assumptions. A production agent answering a single user query might make 7 sequential tool calls: search the knowledge base, retrieve pricing data, calculate discounts, verify inventory, check shipping rates, apply promotions, format the response. Run 10,000 tests in CI, and you’ve made 70,000 API calls. At $0.03 per reasoning step, that’s $2,100 per test suite execution.
Beyond cost, agents introduce a deeper complexity: non-deterministic execution paths. Each test run triggers the agent’s “Reasoning” loop: think about the query, select a tool, observe the result, think again, select another tool, repeat until done.
The path from query to answer isn’t predetermined: it emerges from the reasoning loop. Same query, different runs, different tool sequences.
Traditional software follows deterministic paths. Function A calls function B, which returns value C. You test A with mocked B, verify C appears correctly. Agents reason through possibilities, selecting each tool based on observations from prior steps.

The Multi-Step Testing Challenge
Consider this minimal ReAct agent in LlamaIndex:
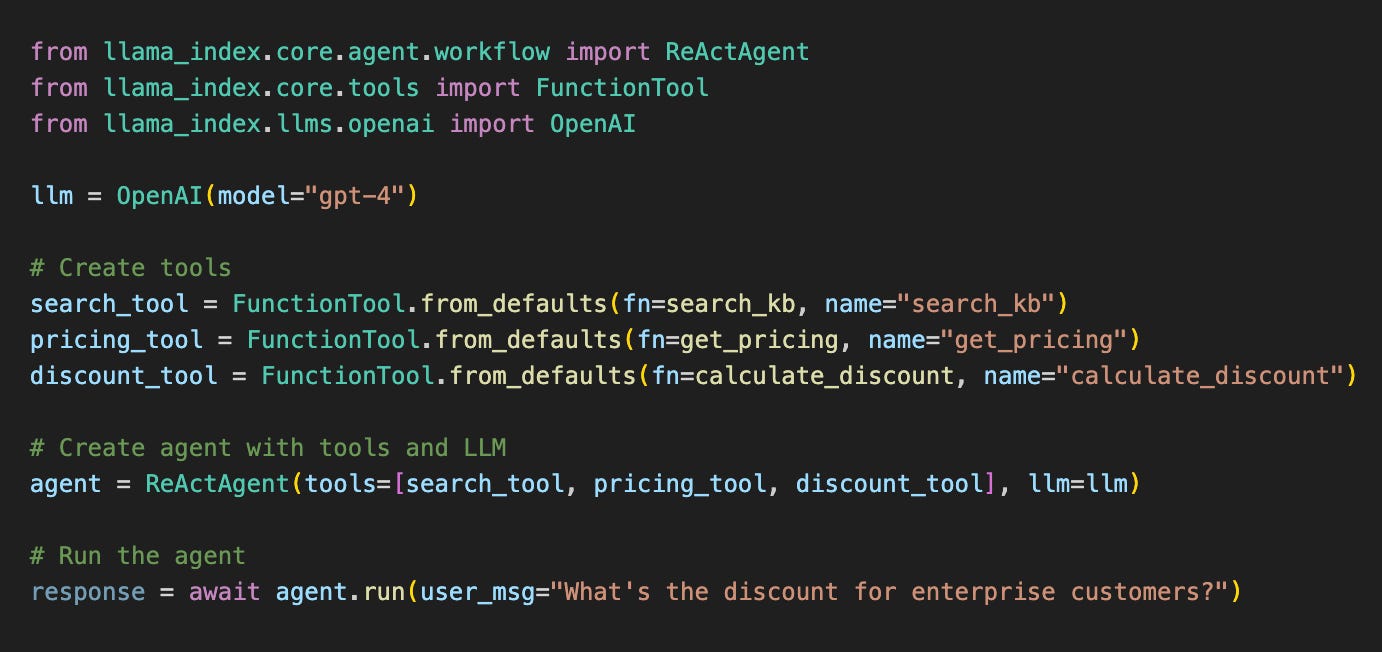
This agent might execute:
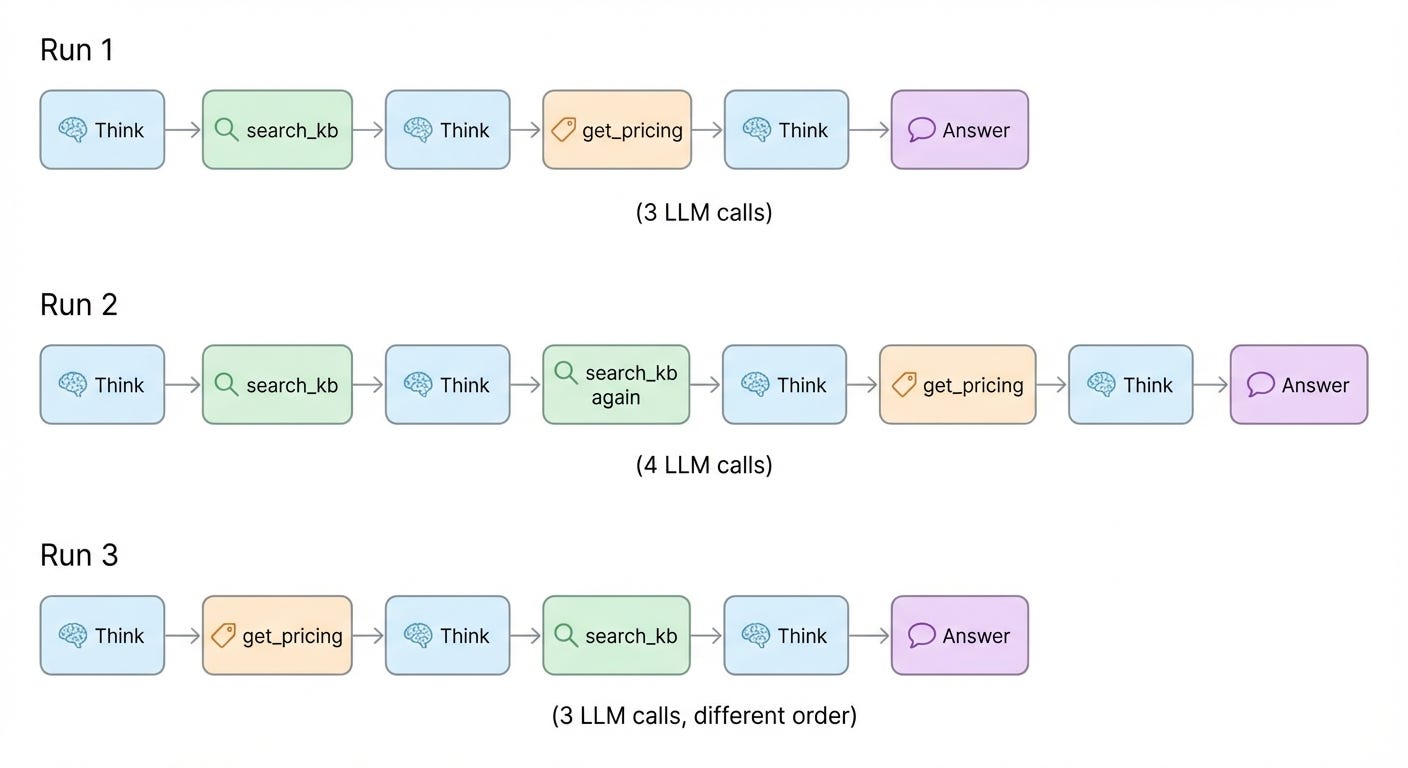
Same query, different paths, all producing valid answers. Now multiply by 10,000 test runs. At roughly $0.03 per reasoning step (averaging 500 input + 200 output tokens with GPT-4), those 3-4 steps cost $900-$1,200 per test suite execution. Run tests on every commit, several times daily across a team, and you’re burning thousands monthly—just on tests.
The traditional response is “mock your external dependencies.” Sure, mock the search_kb tool so it returns canned data. Mock get_pricing to return test values. You still need the LLM to decide which tools to call and when to stop. Without the reasoning engine, you can’t test the agent loop itself. You’re testing individual tools in isolation, not the multi-step orchestration that makes agents different from simple function calls.
This is the agent testing paradox: agents are valuable because they adapt their behavior based on observations, but that same adaptability makes deterministic testing expensive. You need confidence that your agent selects the right tools, handles errors gracefully, and terminates appropriately—without spending hundreds per test run.
The solution is to gain precise control over what the LLM returns at each step.
That’s what reasoning trajectory mocking provides. But before we implement that pattern, we need to clarify what kind of tests we’re actually writing: because agents need two fundamentally different testing strategies.
Deterministic Tests vs Quality Evaluations
Agent systems are hybrid: deterministic software orchestrating non-deterministic LLM outputs. Each half needs its own testing strategy.
Deterministic Testing
When you mock the LLM and verify your agent calls the right tool with the right parameters? That’s deterministic testing. Unit tests check individual tool invocations and error handling. Integration tests verify service boundaries and API contracts. Same input, same output—every time. These run on every commit in CI/CD. This is the Test-Driven Development (TDD) world engineers know.
Quality & Safety Evaluations
These test the content the LLM produces for human consumption. Quality asks: Is this response helpful, accurate, well-formatted? Safety asks: Is it harmful, biased, or policy-violating?
Evaluations run in three modes:
Automatic evaluations: Built alongside the system, run continuously
Production monitoring: Sample live traffic, detect drift
Human SME review: Periodic expert assessment, discover edge cases
Evaluation-Driven Data Science (EDDS)
Just as TDD writes tests before code, EDDS defines evaluations before prompts. The workflow:
Design quality criteria (e.g., “answers cite specific policy sections”)
Build evaluation suite with curated examples
Iterate on prompts until scores improve
Deploy and monitor for drift
Hamel Husain’s “Your AI Product Needs Evals“ (2024) and Eugene Yan’s “Evaluation-Driven Development“ (2023) formalized this practice for production LLM systems. The parallel to TDD is exact: write your quality assertions first, then tune your system to pass them.

This article focuses on deterministic tests—the ones that validate software behavior and run on every commit. We’ll expand on quality evaluations and EDDS in a future article. Right now, we need to solve the testing paradox: how do we steer agent behavior without burning $900 per test run?
Reasoning Trajectory Mocking: Controlling the Reasoning Loop
A ReAct agent executing “What’s the refund policy?” makes a sequence of decisions: think → search → observe → think → respond. Traditional mocks can’t capture this behavior—they handle single calls, not multi-step paths.
Reasoning trajectory mocking pre-defines the exact sequence of LLM responses, letting you steer the entire path. Instead of mocking one API call, you mock the agent’s decision chain:
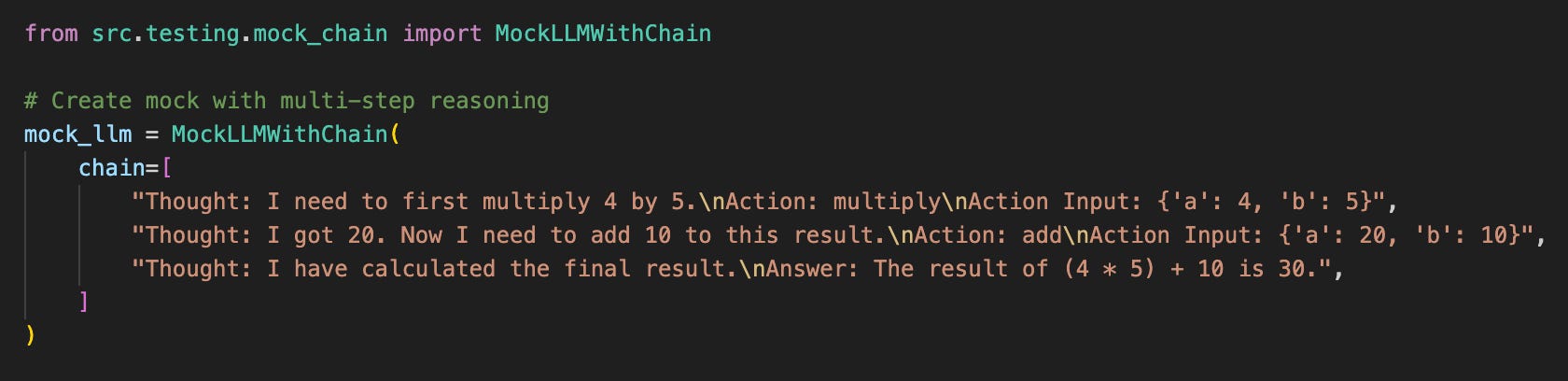
Each string in the chain corresponds to one decision step. The mock returns responses in order, advancing the agent along its pre-defined path. This maps directly to LlamaIndex’s ReActAgent protocol, where each response contains a thought-action pair.
Here’s a complete test defining the full reasoning loop:
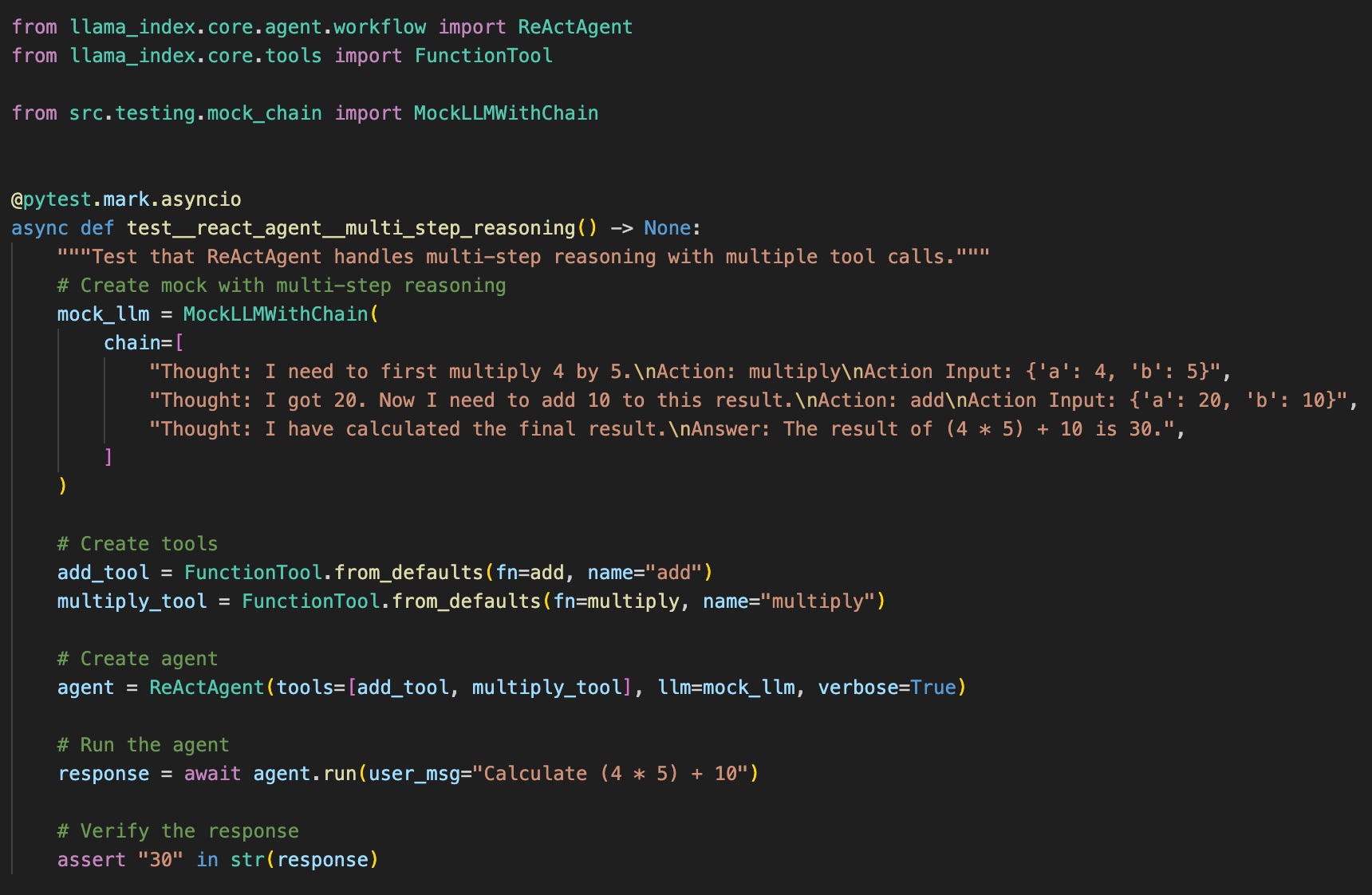
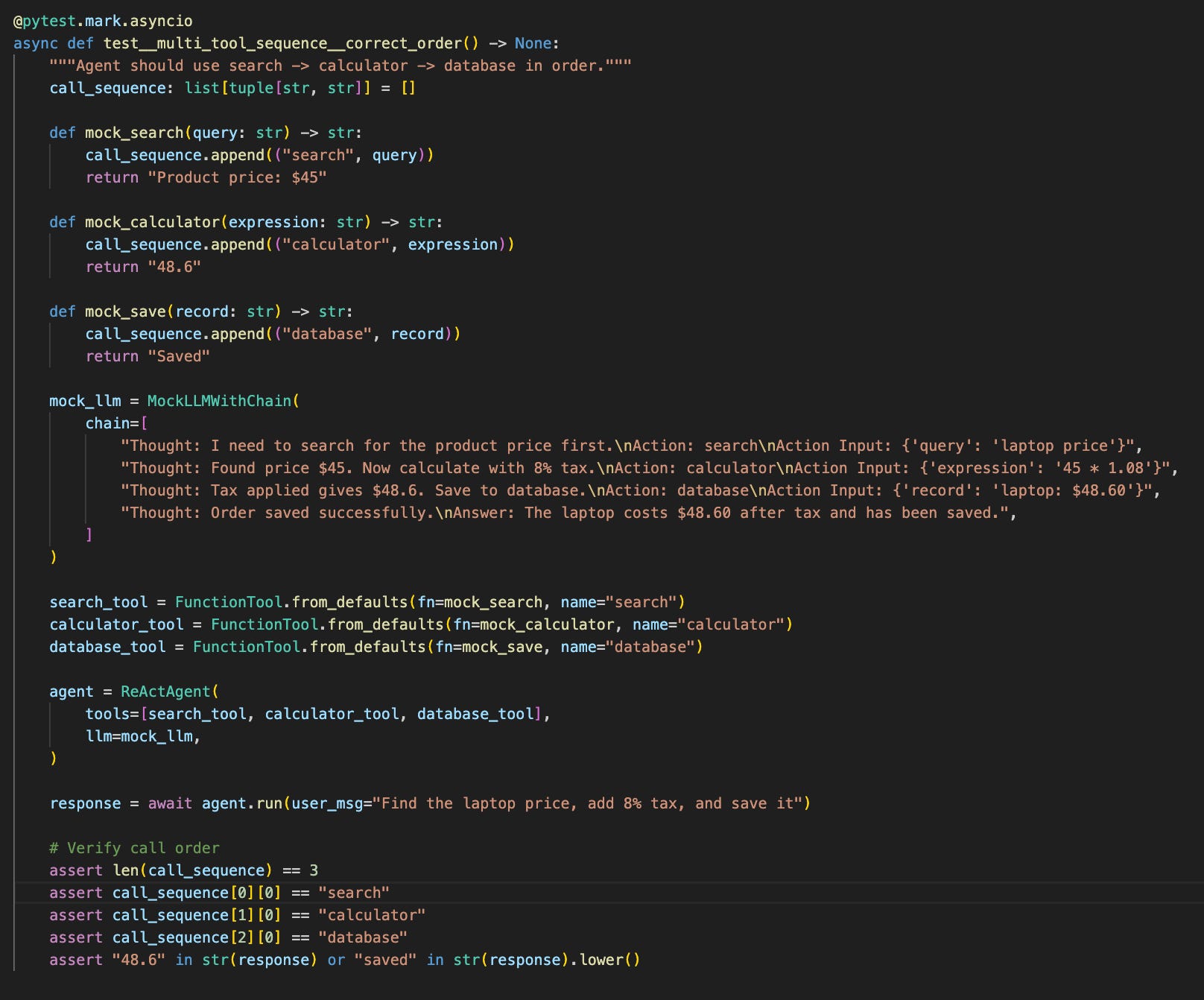
The test defines the exact trajectory the agent will take. Step 1 triggers the search_kb tool. Step 2 uses the tool’s output to generate the final answer. You define what the agent “thinks” at each point along the path.
This same pattern scales to more complex workflows. A data analysis agent running query_database → parse_results → calculate_statistics → generate_chart follows the same structure: each chain entry defines one step, and the test verifies the exact sequence executed.
Cross-Framework Testing Patterns
This mocking pattern works across all three major agent frameworks. The concept stays the same—steering multi-step agent behavior—but neither LlamaIndex nor LangChain provide trajectory mocking out of the box. We built MockLLMWithChain and MockChatModelWithChain to fill this gap. PydanticAI is the exception: it ships with TestModel for structured output testing.
LlamaIndex requires a custom mock. We built MockLLMWithChain implementing the full LLM interface with streaming support:
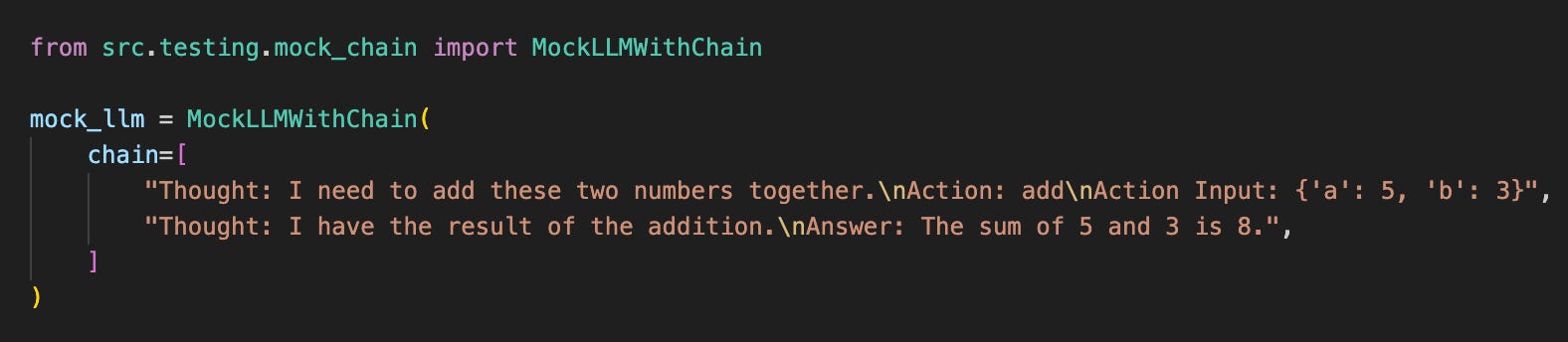
LangGraph also lacks built-in trajectory mocking. We built MockChatModelWithChain extending LangChain's BaseChatModel with automatic tool call parsing:
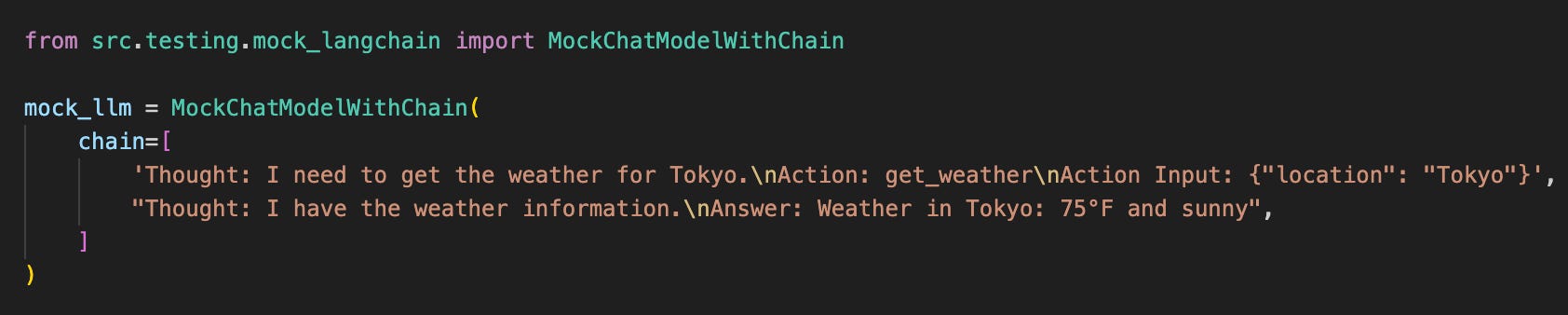
Both custom mocks parse ReAct-style responses automatically. MockLLMWithChain includes streaming support for testing async chat interfaces where character-by-character rendering affects UX. MockChatModelWithChain converts Action patterns into native LangChain tool calls.
PydanticAI ships with built-in testing support. Its native TestModel handles structured output validation:
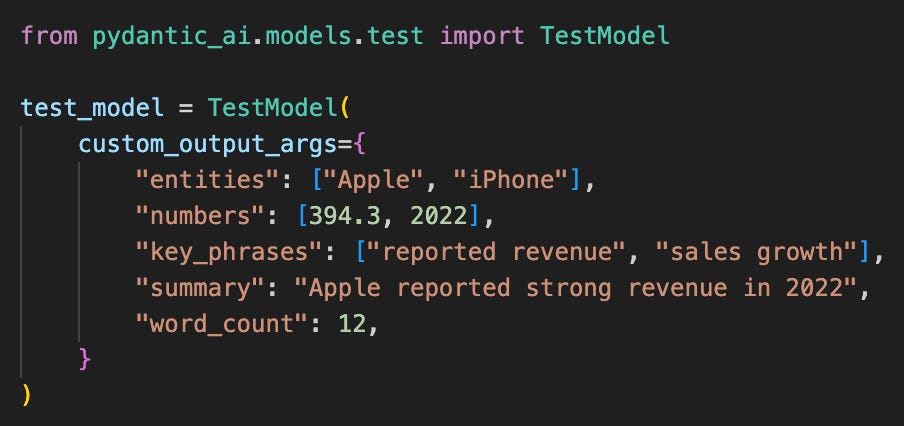
PydanticAI bypasses free-text parsing entirely. This approach shines when testing structured data extraction—no ReAct formatting, just type-checked outputs matching your Pydantic schema.
The harness components from Article 2.1 work identically across all three: planning loops, tool registries, and memory management. The mocks change. The architecture stays constant.
Testing Tool Invocations
Calling delete_user instead of update_user could destroy production data—syntactic correctness won’t save you.
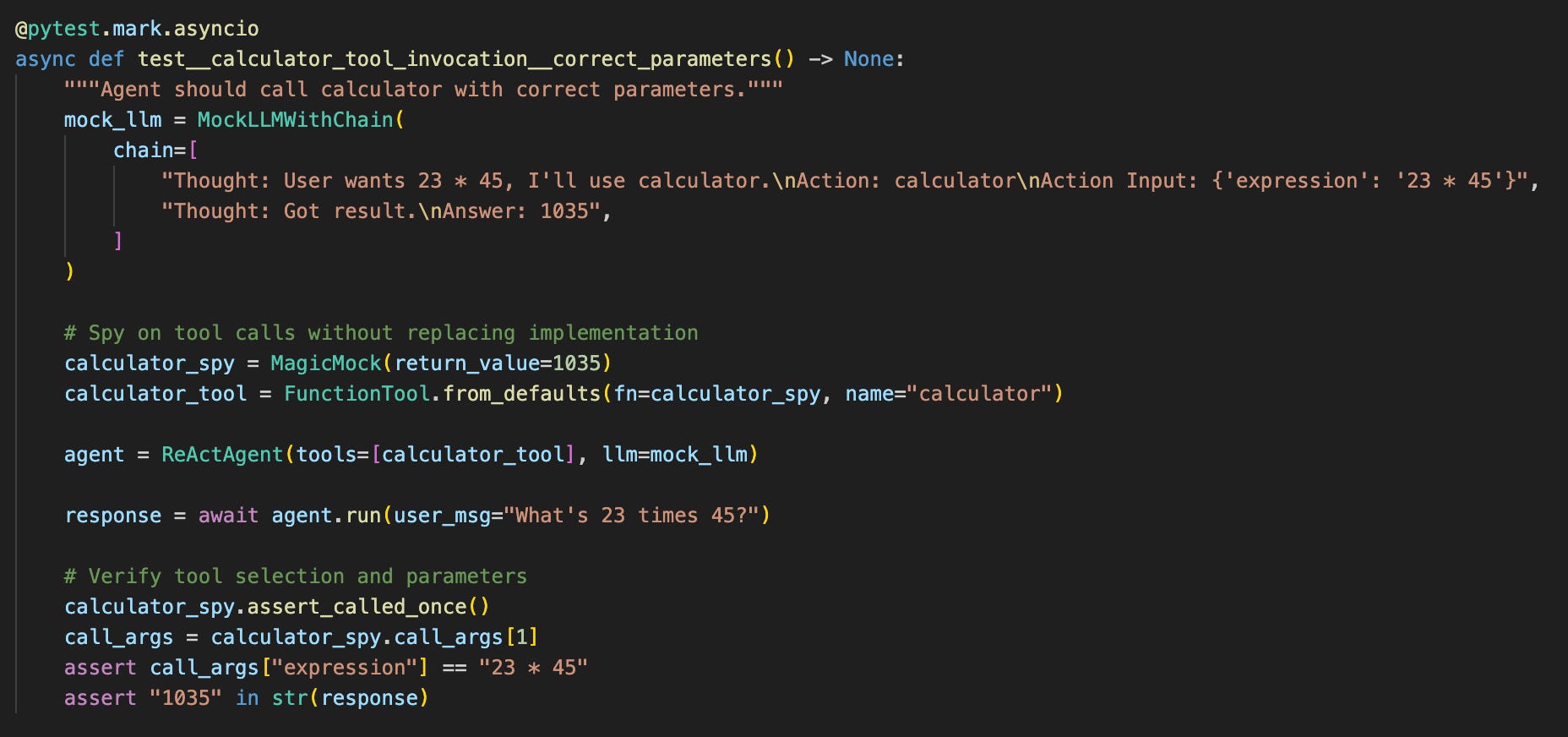
Tool invocation tests verify three critical properties:
Tool selection - Did the agent choose the right tool?
Parameters - Did it pass correct arguments?
Call sequence - Did it use tools in the right order?
Here’s a basic tool invocation test:
Multi-step tool sequences require ordering validation:
Choose your testing pattern based on what you need to verify:

Semantic Assertions for Natural Language Arguments
LLMs rephrase tool arguments constantly, breaking exact string matching. An agent might search for “refund policy” or “policy for refunds”—semantically identical, but == fails. Semantic similarity provides robustness.

Use semantic assertions when:
Tool arguments contain natural language queries
Meaning matters more than exact wording
Stick with exact matching for structured data (IDs, numbers), code, or compliance-critical language.
These patterns test the “execute tools” pillar from Part 2. Tools don’t always succeed though. Let’s test what happens when they fail.
Testing Error Recovery
Production systems fail constantly. Search APIs timeout, rate limits kick in, and responses come back malformed. Production systems see tool failures in roughly 12% of agent interactions. Without proper handling, 68% result in confusing responses or infinite loops.
Trajectory mocking lets you inject failures at specific points and verify graceful degradation. You specify when tools fail, how they fail, and whether the agent adapts appropriately.
Tool Failure Injection
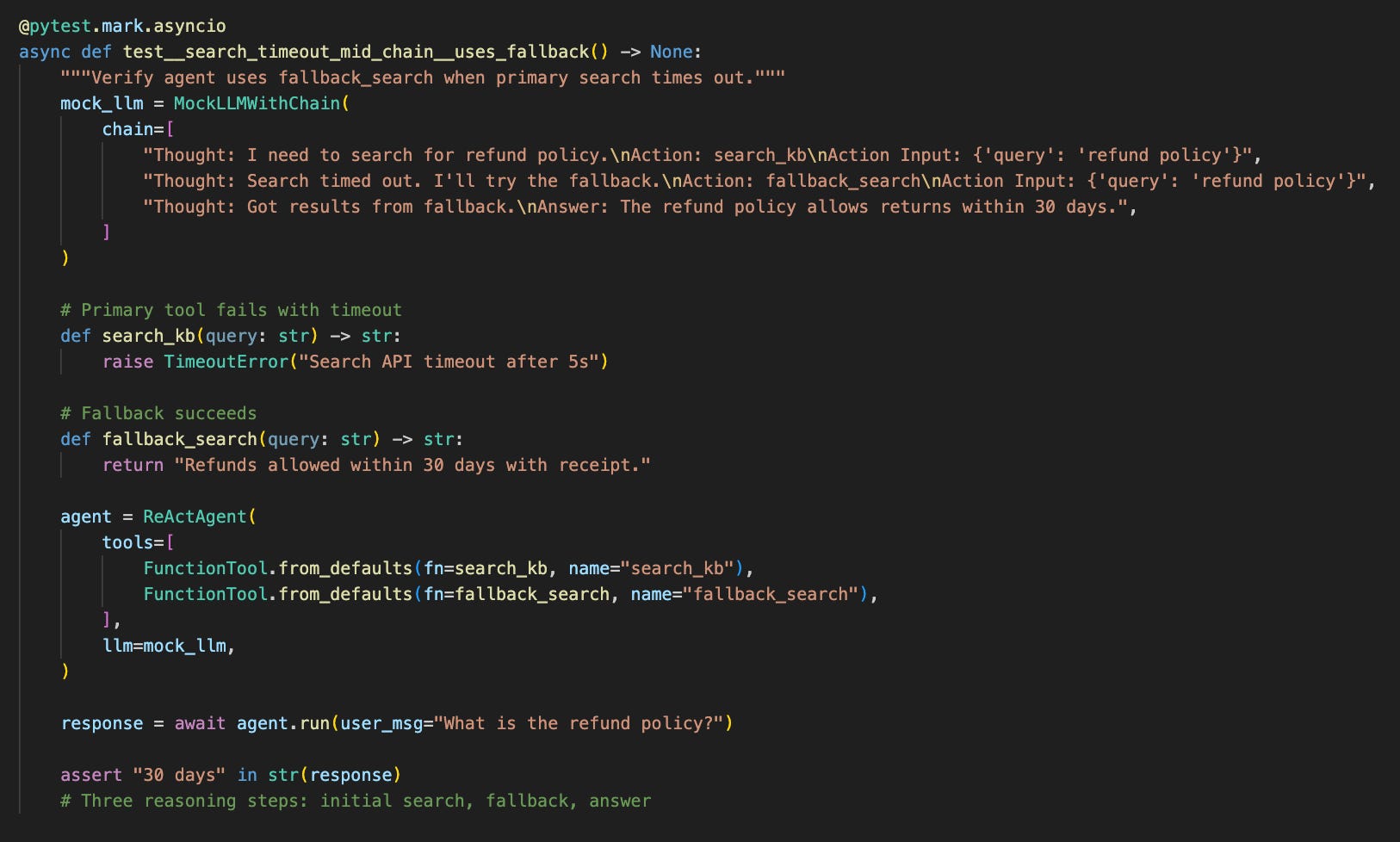
This test simulates a realistic failure scenario. The primary search times out, the agent recognizes the failure in its reasoning chain, and recovers using the fallback tool rather than crashing or looping.
Graceful Degradation
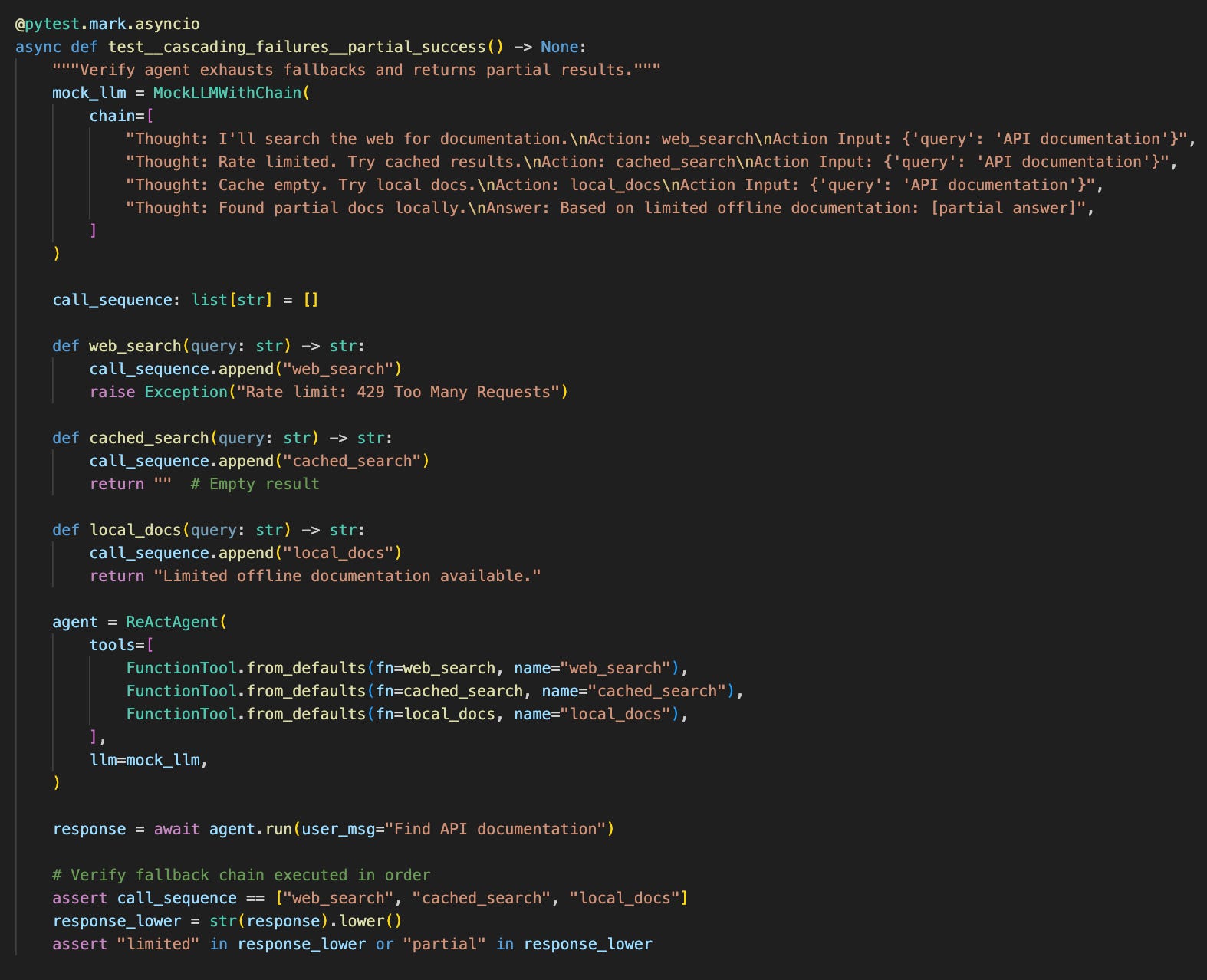
You’re testing the safety layer from Part 2: graceful degradation under cascading failures. The agent encounters rate limits, empty results, and finally succeeds with partial data. It methodically tries alternatives and returns the best available answer.
Error scenarios to test explicitly:
Timeout: Operation exceeds time limit
API error: 429, 500, 503 responses
Empty result: Valid response, no data
Exception: Unexpected failures
Cascading failures: Multiple tools fail sequentially
Failure handling determines whether your agent helps users or frustrates them. Treat it as a core feature. Test it explicitly.
Implementation Roadmap
Start with your existing agents and build coverage incrementally.
Phase 1: Establish Baseline
Map what you already have:
[ ] Identify agents using tools (grep for
ReActAgent.from_toolsor similar)[ ] Run agents with verbose logging to trace actual reasoning chains
[ ] Document 3-5 most common tool sequences (search → retrieve → format)
Phase 2: Build Happy Path Coverage
[ ] Write tool invocation tests for each tool your agents use
[ ] Create chain fixtures for common behaviors (target 80% of observed sequences)
[ ] Validate mocked chains produce expected final outputs
Phase 3: Add Error Resilience
[ ] Add error injection tests (API failures, timeouts, invalid tool args)
[ ] Test recovery paths: Does the agent retry? Fall back? Abort gracefully?
[ ] Create fixtures for error scenarios
Phase 4: Measure Impact
[ ] Track coverage: % of observed sequences tested vs seen in production
[ ] Calculate cost savings:
test_runs × avoided_API_calls × $0.03/call[ ] Document edge cases discovered during testing
Reference Implementation: See the complete agent testing suite with examples for LlamaIndex, LangGraph, and PydanticAI.
Testing agent reasoning doesn’t mean running expensive models on every commit. With trajectory mocking, you control thoughts, actions, and observations at each step—catching infinite loops before production, validating tool selection without hitting real APIs, and verifying error recovery without waiting for actual failures. The difference between a $2,100 test suite and a zero-cost test suite is precise control over multi-step agent behavior.
Next: This article covered deterministic testing fundamentals: reasoning trajectory mocking, tool invocation testing, and error recovery. Article 3.1 goes deeper into advanced patterns—trajectory validation, state machine testing, memory retention, and regression testing. Together, they give you complete coverage of the six canonical harness components from Article 2.1.
AI Agents in Production Series
The Three-Layer Architecture: The Harness, the Model, and the Loop
Deterministic Testing with Trajectory Mocking ← You are here
LlamaIndex vs PydanticAI vs LangGraph
Agent Observability: Traces, Evals, Alerts
5 Agentic Design Patterns That Actually Work