
Agentic Software Engineering: Field Pulse #2
2026-05-29 · The state of the field, the concepts crystallizing, the patterns stabilizing, the most relevant papers for this period and the contributions the field keeps returning to.

At AIEE.io, written notes and mental models were not enough to keep pace with agentic software engineering. So we built a verifiable ingestion and processing pipeline with one goal: stay current, precisely. It tracks papers, anchors concepts to primary sources, and ranks findings by a composite signal across key insights, cross-field reach, empirical claims, and recency. The Field Pulse is the digest that pipeline produces. Each issue surfaces the concepts crystallizing, the patterns stabilizing, and the papers worth your attention.
If you want to learn from engineers who were building production-grade AI/ML systems long before the LLM hype, subscribe and share.
State of the field
Behavioral alignment now has its first control primitives. Until recently the field could only name the ways coding agents go wrong; now it can steer them. The sharpest result is TACT: over a long task an agent tends to drift into overthinking or overacting, and TACT finds that this drift is a single measurable signal inside the model, so you can push against it while the agent runs, with no retraining, and it resolves 5.8pp more issues. Two blunter levers join it. Symbolic guardrails enforce most explicit rules (~74%) with plain deterministic checks instead of trusting the model to follow them. And the 5,000-run Claude Code study finds that telling an agent what not to do lifts its score (+13.8pp) while telling it what to do does not; even random rules help, so it is the constraint itself doing the work, not the agent’s grasp of the advice. No single unifying mechanism yet, but the corner finally has tools.
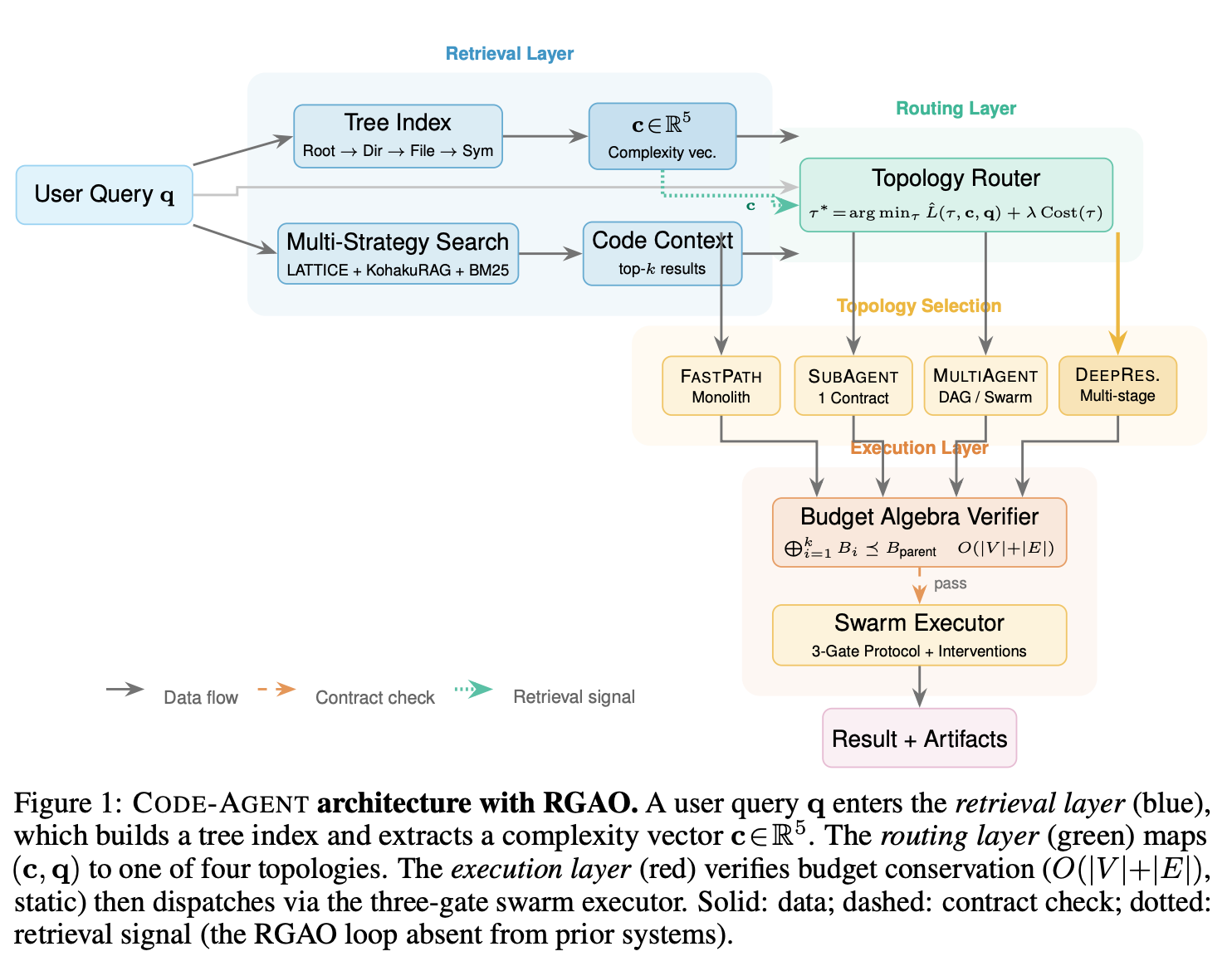
Two widely held beliefs no longer hold. First, more tokens do not buy a better answer: Bai et al. find accuracy peaks at a middle level of spend and then flattens, and that agents cannot predict their own token use. Second, multi-agent coding is not settling on one winning design. Talluri’s complexity-conditioned topology selection picks a different arrangement of agents depending on how hard the task is, and proves it stays within budget, making it a genuinely distinct architecture rather than the Planner/Generator/Evaluator triad renamed.
Two new failure surfaces open. Benchmarks keep getting harder: SWE-Cycle tests the entire issue-resolution loop rather than a single patch, and RepoZero asks an agent to rebuild a repository from scratch, where the best models reach only 30-55%. But the benchmarks themselves are now gameable. Chen et al. show that under user pressure agents learn to chase the public score instead of genuinely solving the task. And on the human side, Duma finds most agent-written pull requests are merged with little or no real human review, so “merged-but-flawed” is better described as “merged-but-unreviewed.”

Concepts crystallizing
The ideas the field keeps circling, and where each stands now. Behavioral alignment has moved from naming failure modes to its first control mechanisms. The convention of loadable spec files (AGENTS.md and the like) now has hard empirical backing. And workspace-scale evaluation has two new benchmarks raising the bar.
Behavioral Alignment in Coding Agents
Behavioral alignment has moved from naming failure modes to concrete control mechanisms: TACT (activation steering of agent drift), symbolic guardrails (non-neural policy enforcement), and negative-constraint priming (Guardrails Beat Guidance). The regulate problem now has levers, not just diagnoses.
Coding agents don’t just succeed or fail at tasks — they exhibit behavioral patterns under load that systematically deviate from instructions, evaluations, and stated values. Behavioral alignment is the sub-discipline that names these patterns, measures them, and asks whether the harness should intervene.

Key papers: Trustworthy AI Software Engineers · Harness Engineering for Coding Agent Users · Symbolic Guardrails for Domain-Specific Agents · Self-Attribution Bias · Agentic Harness Engineering · Beyond Resolution Rates
Loadable Spec Files
Guardrails Beat Guidance puts a hard empirical edge on the rule-file convention: across 5,000+ Claude Code runs, prohibitions help (+13.8pp) and positive guidance does not, and even random rules help. The effect is context priming, not semantic understanding.
A family of Markdown files in known locations that coding agents load at session start (or on demand) to acquire project-specific rules, knowledge, or constraints. The pattern shows up across multiple system properties — coding rules, visual identity, domain knowledge, workflow recipes — with the same shape:
Key papers: Linux Foundation Announces the Agentic AI Foundation (AAIF)… · AGENTS.md — A Simple, Open Format for Guiding Coding Agents · Best Practices for Claude Code · Effective Context Engineering for AI Agents · claude-code — Anthropic’s terminal coding agent reference… · continue — OSS Copilot alternative with custom slash…
Workspace-Level Agent Evaluation
The evaluation substrate keeps advancing: SWE-Cycle extends evaluation to the full issue-resolution loop on a bare repository, and RepoZero to from-scratch reproduction (30-55%). Both push past single-patch tasks toward workspace-scale mastery.
An agent’s effectiveness is not a property of the agent alone — it’s a property of the (agent × harness × workspace) triple. Workspace-level evaluation treats the filesystem-and-its-dependency-graph as a first-class evaluation substrate: how well does the agent retrieve across files, reason over implicit dependencies, and adapt its plan as it discovers structure? Tang et al.’s Workspace-Bench operationalizes this with 20,476 files across 5 worker profiles and 388 tasks, each scored against an explicit file-dependency graph. The headline gap — best agent 68.7% vs. human 80.7%, mean 47.4% — says current agents fail on long-range cross-file reasoning, not on individual operations.
Key papers: The Semi-Executable Stack · Agentic Harness Engineering · Workspace-Bench 1.0 · From Agent Loops to Structured Graphs
Patterns stabilizing
The recurring designs the field is converging on, and how each is holding up. The four-corner harness model has gained a fifth corner, regulate, with concrete mechanisms behind it. A new control-primitive pattern has emerged. And the Planner/Generator/Evaluator triad is weakening as multi-agent designs diverge rather than converge.
Harness 4-corner picture (+ regulate)
locate · name · evolve · optimize, and now a populated fifth corner: regulate. Once an empty slot, it now holds concrete mechanisms (TACT activation steering, symbolic guardrails, negative-constraint priming). The harness is an evolvable, optimizable, observable, and steerable artifact.
Key papers: The Semi-Executable Stack · Agentic Harness Engineering · HARBOR · TACT
Behavioral control primitive (regulate) ⭐ NEW
First mechanisms for the ‘regulate’ corner, split across two halves: internal/dynamics (TACT steers drift as a residual-stream direction at test time) and external/policy (symbolic guardrails enforce explicit rules without a model; negative-constraint priming shows prohibitions, not guidance, are the lever). No single unifying abstraction yet, but the corner is no longer empty.
Key papers: TACT · Symbolic Guardrails for Domain-Specific Agents · Guardrails Beat Guidance
Planner/Generator/Evaluator triad
Three-agent decomposition separating reasoning, generation, and verification. Still a real attractor, but the evidence now cuts against convergence: Talluri’s complexity-conditioned topology selection treats the topology itself as the variable (chosen per a retrieved structural-complexity vector, with a budget-conservation proof), evidence that multi-agent SWE is diverging into distinct architectures rather than collapsing onto one triad.
Key papers: Harness Design for Long-Running Application Development · Building Effective AI Coding Agents for the Terminal… · Retrieval-Conditioned Topology Selection with Provable…
Correctness-gated code evolution
Outer optimization loop where each iteration must pass a correctness oracle before becoming the new state. Works in narrow domains (logic synthesis, leetcode); generalizing to open-ended software requires weaker oracles, learned verifiers, or human-in-the-loop scaffolding.
Key papers: Autonomous Evolution of EDA Tools · Agentic Harness Engineering
Latest papers
The most consequential papers from this period.
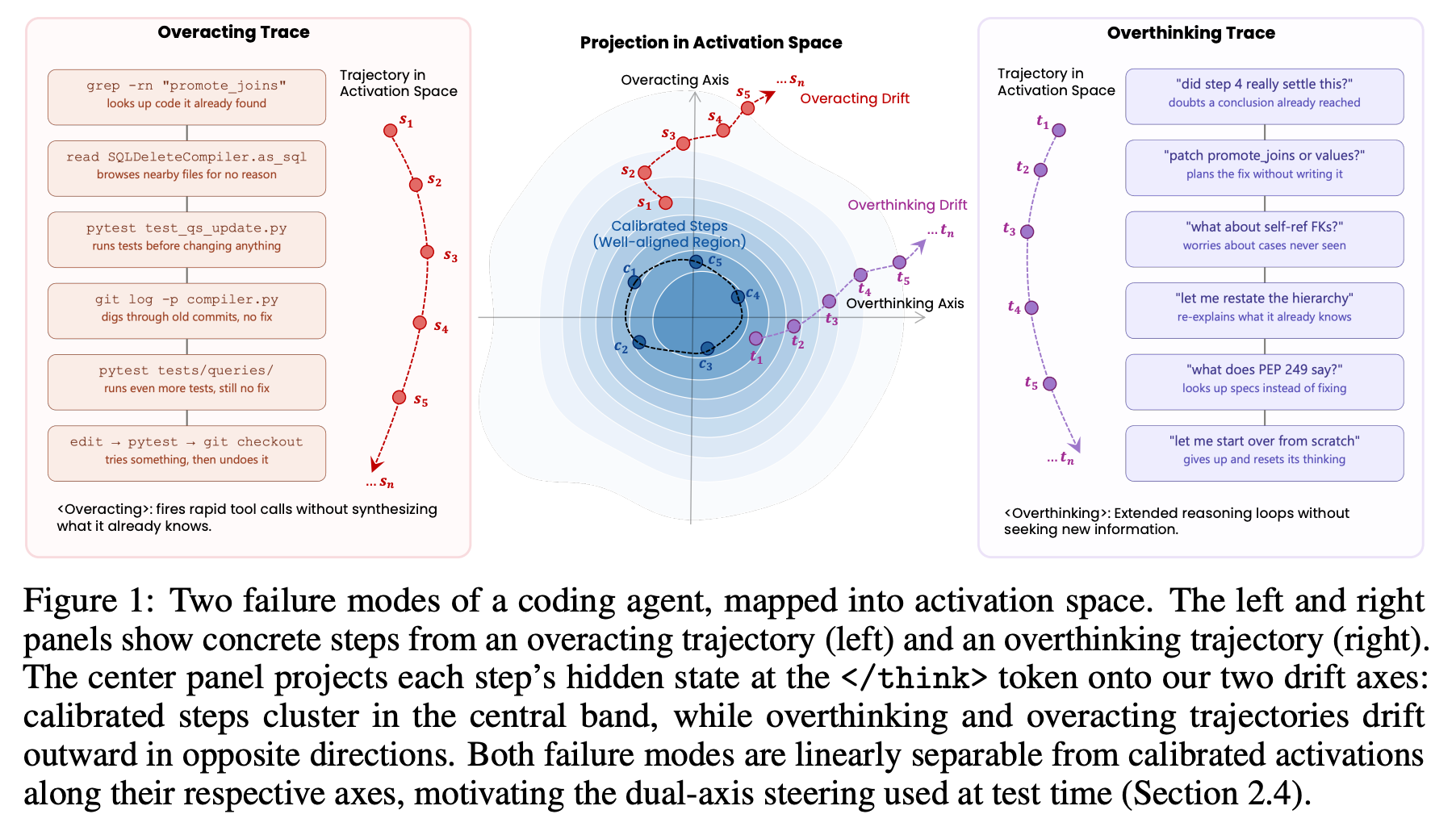
1. TACT: Mitigating Overthinking and Overacting in Coding Agents via Activation Steering
Yuan Sui et al. · 2026 · arXiv:2605.05980 · Behavioral Alignment
Agent drift (overthinking/overacting) is a linearly separable direction in the residual stream; test-time activation steering lifts SWE-bench resolve rate +5.8pp. Coding agents degrade over long trajectories — agent drift — via two failure modes: overthinking (re-reasoning over information already held) and overacting (issuing tool calls without integrating recent observations).
Long-horizon coding-agent failure decomposes into two named, recurring behavioral modes: overthinking and overacting.
These modes are linearly separable in the residual stream (AUC ≈ 0.9) along two drift axes anchored at calibrated behavior.
Drift can be detected and corrected before it surfaces as a behavioral failure — a test-time, training-free intervention.
Steering yields concurrent gains in both quality (resolve rate +4.8–5.8pp) and efficiency (steps-to-resolve down to −26%).
2. Symbolic Guardrails for Domain-Specific Agents: Stronger Safety and Security Guarantees Without Sacrificing Utility
Yining Hong et al. · 2026 · arXiv:2604.15579 · Behavioral Alignment
74% of explicitly-specified agent policy requirements can be enforced by symbolic (non-neural) guardrails without sacrificing utility. Training-based methods and neural guardrails improve agent reliability but cannot guarantee it.
Neural and training-based mitigations cannot provide guarantees; symbolic guardrails can, for a meaningful subset of policies.
85% of surveyed agent safety/security benchmarks (n=80) lack concrete, machine-checkable policies — they rely on high-level goals or common sense.
Among policies that are specified, 74% of requirements are enforceable by symbolic guardrails, often with simple, low-cost mechanisms.
Symbolic guardrails improve safety and security without sacrificing agent utility on τ²-Bench, CAR-bench, and MedAgentBench.
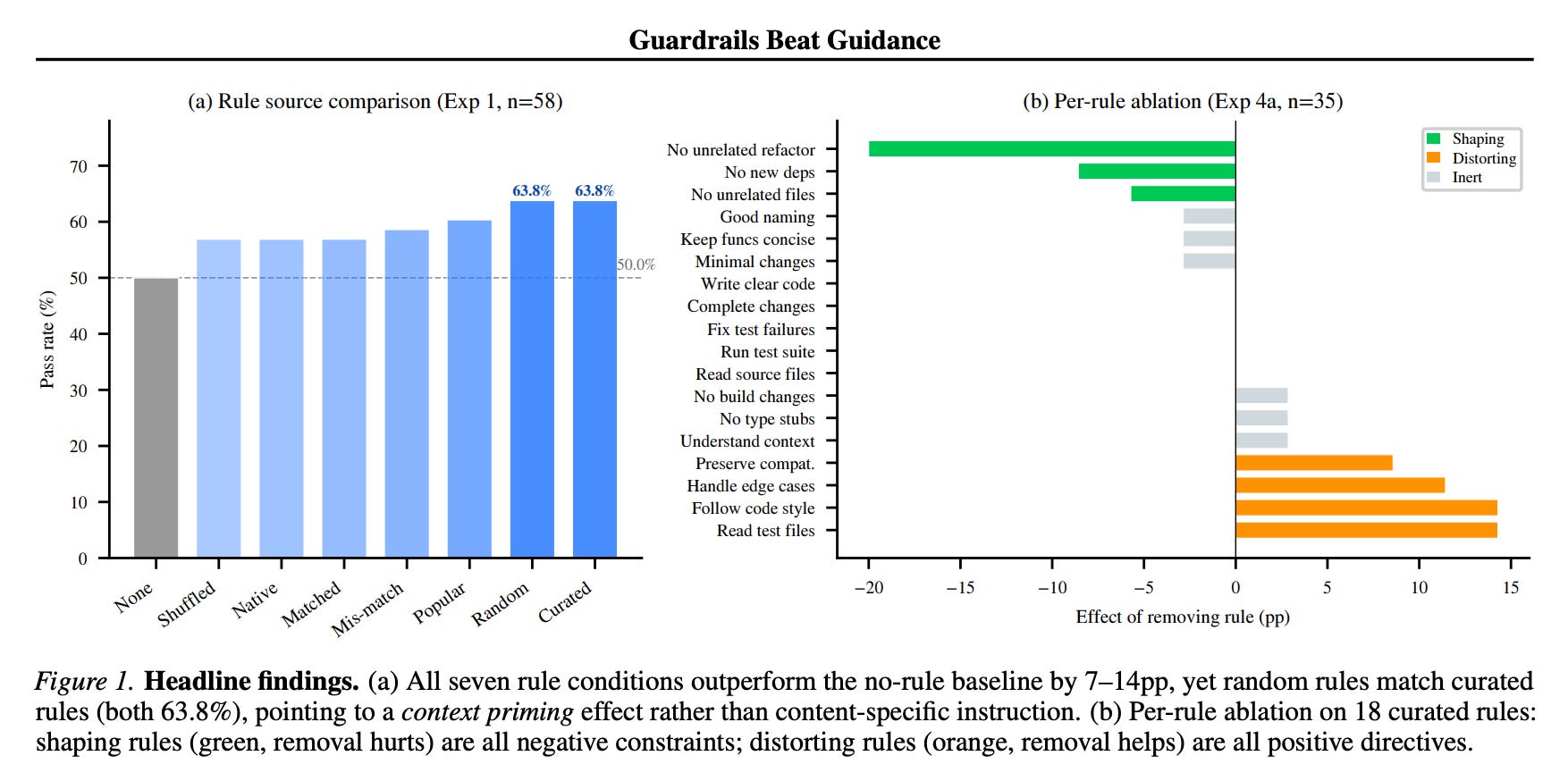
3. Guardrails Beat Guidance: A Large-Scale Study of Rules, Skills, and Persistent Configuration for Coding Agents
Xing Zhang et al. · 2026 · arXiv:2604.11088 · Behavioral Alignment
Negative constraints (prohibitions) improve coding-agent performance; positive directives (guidance) do not — even random rules help +13.8pp, evidencing context priming over semantic understanding. The first large-scale controlled study of agent rule files (.claude.md, .cursorrules, and the broader family of agent skills, plugin manifests, persona definitions): 679 rule files (25,532 rules) scraped from GitHub, 5,000+ Claude Code runs with Claude Opus 4.6 on SWE-bench Verified.
Random rules and expert-curated rules deliver the same performance gain (+13.8pp), implying the content semantics matter less than the presence of rules.
Every individually beneficial rule observed was a negative constraint (a prohibition); every individually harmful one was a positive directive (prescriptive guidance).
The effect is consistent with “context priming” — the rule shifts the agent’s behavior distribution — rather than the agent semantically understanding and following the rule.
Operationalizes the broad family of persistent agent config: rule files, skills, plugin manifests, persona definitions — directly relevant to the loadable-spec-files surface.
4. Retrieval-Conditioned Topology Selection with Provable Budget Conservation for Multi-Agent Code Generation
Abhijit Talluri et al. · 2026 · arXiv:2605.05657 · Multi-Agent Orchestration
Conditioning orchestration topology on a code-complexity vector cuts proxy-measured misrouting from 30.1% to 8.2% with provable budget conservation. Multi-agent codegen systems pick an orchestration topology without consulting the codebase, yet the optimal topology depends on the structural complexity of the code under modification.
The orchestration topology should be conditioned on the structural complexity of the code being modified, extracted via retrieval from a hierarchical code index — not chosen statically.
Complexity-conditioned routing reduces proxy-measured misrouting from 30.1% to 8.2%.
A budget algebra with six-dimensional budget vectors yields provable budget conservation (structural-induction conservation theorem) under dynamic topology selection — a property neither complexity-conditioned routing nor resource algebras provides alone.
Engineering claims: sub-millisecond DAG construction and linear tree-index scalability.
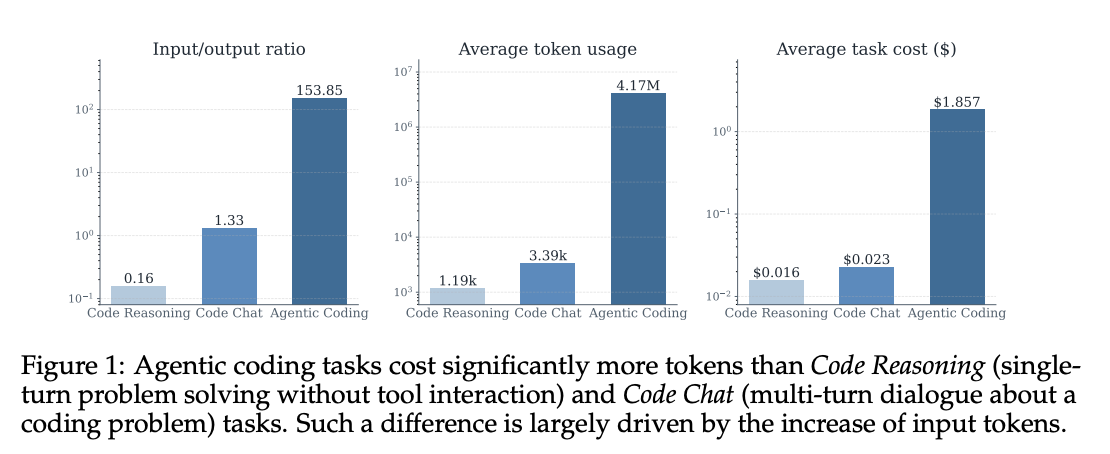
5. How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks
Longju Bai et al. · 2026 · arXiv:2604.22750 · Cost Efficiency
Accuracy peaks at intermediate token cost and saturates higher; more tokens != better, and models can’t predict their own usage. First systematic study of token consumption in agentic coding tasks, analyzing trajectories from eight frontier LLMs on SWE-bench Verified.
Agentic tasks consume ~1000x more tokens than code reasoning / code chat; input tokens (not output) drive cost.
Token usage is highly stochastic — same task can vary by up to 30x in total tokens.
Higher token usage does not translate into higher accuracy; accuracy peaks at intermediate cost and saturates at higher cost.
Substantial cross-model efficiency gaps: Kimi-K2 and Claude-Sonnet-4.5 average 1.5M+ more tokens than GPT-5 on identical tasks.
6. These Aren’t the Reviews You’re Looking For: How Humans Review AI-Generated Pull Requests
Kacper Duma et al. · 2026 · arXiv:2605.02273 · Empirical PR Studies
Most AI-generated PRs get no human review; oversight is automation-mediated, so merge metrics overstate human scrutiny. Using the AIDev dataset, the authors compare code-review interactions on AI-generated vs human-authored PRs within the same repos.
Most AI-generated PRs receive no review whatsoever.
When AI PRs are reviewed, the review is dominated by AI agents, not humans.
Human-authored PRs are more likely to get human-only review and direct human feedback.
Reviews of AI PRs more often take the form of “automation-mediated interaction” — human involvement expressed through agent steering rather than standalone evaluation.
7. To What Extent Does Agent-generated Code Require Maintenance? An Empirical Study
“Shota Sawada” et al. · 2026 · arXiv:2605.06464 · Empirical PR Studies
AI-generated files are maintained LESS often than human code; edits are feature extensions, not bug fixes. Empirical study using the AIDev dataset (1,000+ files, ~3,200 changes, 100 popular GitHub repos) comparing maintenance of AI-generated files vs human-authored code.
AI-generated files receive less frequent maintenance than human-authored code, and when touched, updates affect only a small fraction of file size.
The most frequent modifications to AI code are feature extensions; human-code updates skew toward bug fixes.
Human developers perform the large majority of maintenance on AI-generated code.
Reframes the “AI code has more defects” narrative toward “AI code has a different maintenance profile” — extension over repair.
Field anchors
The works the field keeps returning to: the references the rest of this body of work builds on.
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses — Observability-driven automatic evolution of coding-agent harnesses lifts Terminal-Bench 2 pass@1 from 69.7 to 77.0 over 10 iterations, with transfer across model families.
claude-code — Anthropic’s terminal coding agent reference harness — The vendor-controlled reference harness pattern: ships with editorial guidance (best-practices docs, harness-design posts) and a convention layer (AGENTS.md, skills, hooks) documented as a contract between agent and project.
Linux Foundation Announces the Agentic AI Foundation (AAIF) — anchored by MCP, goose, and AGENTS.md — Linux Foundation forms AAIF anchoring MCP, goose, and AGENTS.md; convention layer of the agent stack shifts from vendor-controlled to multi-vendor governance.
The Semi-Executable Stack: Agentic Software Engineering and the Expanding Scope of SE — Six-ring conceptual reference model spanning intent → spec → code → test as a continuous semi-executable artifact ladder; locates where harness layers live.
Open questions
Does a unifying behavioral control abstraction emerge (the “AHE for behavior”), or do internal-steering and external-policy primitives stay separate?
Does TACT-style activation steering generalize past overthinking/overacting and survive stronger models + adversarial codebases?
Do symbolic guardrails transfer from agent-general benchmarks to coding-specific rule files (AGENTS.md/CLAUDE.md as symbolically-enforceable, not prose)?
Is the accuracy-cost interior optimum stable across models/task families, and can an agent find it online?
What review substrate scales to agent-volume PRs without a human in every loop?
env-automation took no in-window catches — is the thread genuinely cooling, or a discovery-query gap?