
Agentic SWE: Field Pulse #1
2026-05-10 · State of the field, the concepts crystallizing, the patterns stabilizing, and this pulse's top 7 papers.

At AIEE.io, written notes and mental models were not enough to keep pace with agentic software engineering. So we built a verifiable ingestion and processing pipeline with one goal: stay current, precisely. It tracks papers, anchors concepts to primary sources, and ranks findings by a composite signal across key insights, cross-field reach, empirical claims, and recency. The Field Pulse is the digest that pipeline produces. Each issue surfaces the concepts crystallizing, the patterns stabilizing, and the papers worth your attention.
If you want to learn from engineers who were building production-grade AI/ML systems long before the LLM hype, subscribe and share.
State of the field
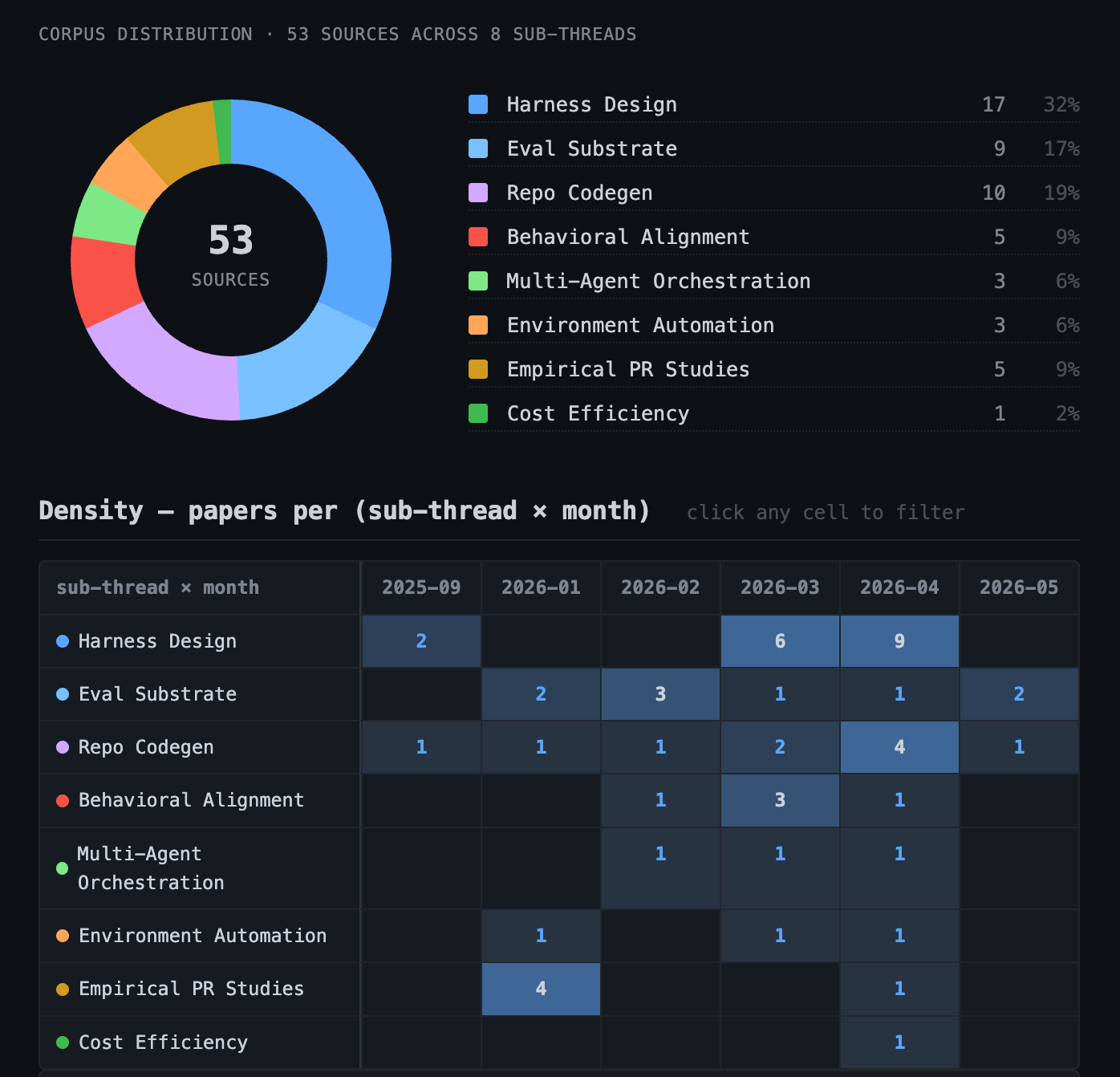
Coding agents are moving from prompt-and-pray to engineered harnesses with observability-driven evolution (Lin AHE) and bounded BO optimization (Sengupta HARBOR). The bootstrap pulse opened a fifth corner the field had been ignoring: behavioral alignment, where five Jan-Apr papers name distinct failure modes (goal drift, self-monitoring biases, motivation-framing sensitivity, behavioral drift between LLMs, unmeasurable trustworthiness) that share a thread: behavior is a target of design, not just an emergent property of the model. The eval-substrate wave the May-6 framing called emergent has been quietly cresting since January (OctoBench, ABC-Bench, SWE-Refactor, CktEvo, FeatureBench predate Workspace-Bench / POSTCONDBENCH).

Concepts crystallizing
Selected concepts for this pulse.
Behavioral Alignment in Coding Agents — ⭐ NEW
NEW corner opened this pulse — 5 Jan-Apr papers (Saebo, Khullar, Wu, Mehtiyev, Aleti) anchor a fifth ‘regulate’ axis to the harness picture.
Coding agents don’t just succeed or fail at tasks — they exhibit behavioral patterns under load that systematically deviate from instructions, evaluations, and stated values. Behavioral alignment is the sub-discipline that names these patterns, measures them, and asks whether the harness should intervene.
Anchored by: Trustworthy AI Software Engineers · Harness Engineering for Coding Agent Users · Self-Attribution Bias · Agentic Harness Engineering · Beyond Resolution Rates · Asymmetric Goal Drift in Coding Agents Under Value Conflict · +2 more
Loadable Spec Files
Linux Foundation governance moment under AAIF (60K+ repos, 30+ tools, 170+ orgs) shifts the convention layer of the agent stack from vendor-controlled to multi-vendor governance.
A family of Markdown files in known locations that coding agents load at session start (or on demand) to acquire project-specific rules, knowledge, or constraints. The pattern shows up across multiple system properties — coding rules, visual identity, domain knowledge, workflow recipes — with the same shape:
Anchored by: Linux Foundation Announces the Agentic AI Foundation (AAIF)… · AGENTS.md — A Simple, Open Format for Guiding Coding Agents · Best Practices for Claude Code · Effective Context Engineering for AI Agents · CLAUDE.md, AGENTS.md & Copilot Instructions · LLM-Assisted Repository-Level Generation with Structured…
Workspace-Level Agent Evaluation
Workspace-Bench formalizes the eval substrate beyond task completion — filesystem and dependency graph as the testbed, not the harness.
An agent’s effectiveness is not a property of the agent alone — it’s a property of the (agent × harness × workspace) triple. Workspace-level evaluation treats the filesystem-and-its-dependency-graph as a first-class evaluation substrate: how well does the agent retrieve across files, reason over implicit dependencies, and adapt its plan as it discovers structure? Tang et al.’s Workspace-Bench operationalizes this with 20,476 files across 5 worker profiles and 388 tasks, each scored against an explicit file-dependency graph. The headline gap — best agent 68.7% vs. human 80.7%, mean 47.4% — says current agents fail on long-range cross-file reasoning, not on individual operations.
Anchored by: The Semi-Executable Stack · Agentic Harness Engineering · Workspace-Bench 1.0 · From Agent Loops to Structured Graphs
Patterns stabilizing
Selected patterns for this pulse.
Harness 4-corner picture
locate · name · evolve · optimize — possibly a 5th corner: regulate. The harness as an evolvable, optimizable, observable artifact, not just runtime infrastructure.
Anchored by: The Semi-Executable Stack · Agentic Harness Engineering · HARBOR
Planner/Generator/Evaluator triad
Three-agent decomposition where reasoning, generation, and verification are separated. Structurally distinct from single-agent loops; converging on multi-vendor consensus (Anthropic Applied AI + OPENDEV + emerging multi-agent orchestration papers).
Anchored by: Harness Design for Long-Running Application Development · Building Effective AI Coding Agents for the Terminal…
Correctness-gated code evolution
Outer optimization loop where each iteration must pass a correctness oracle before becoming the new state. Works in narrow domains (logic synthesis, leetcode); generalizing to open-ended software requires weaker oracles, learned verifiers, or human-in-the-loop scaffolding.
Anchored by: Autonomous Evolution of EDA Tools · Agentic Harness Engineering
Top 7 papers
Ranked by an 8-signal share-worthiness composite: key-insight thread, vocabulary, cross-field reach, substantial My Take, empirical claims, log-inbound citations, wildcard, recency decay. Hooks are verbatim from each paper’s abstract. No LLM rewriting at render time.
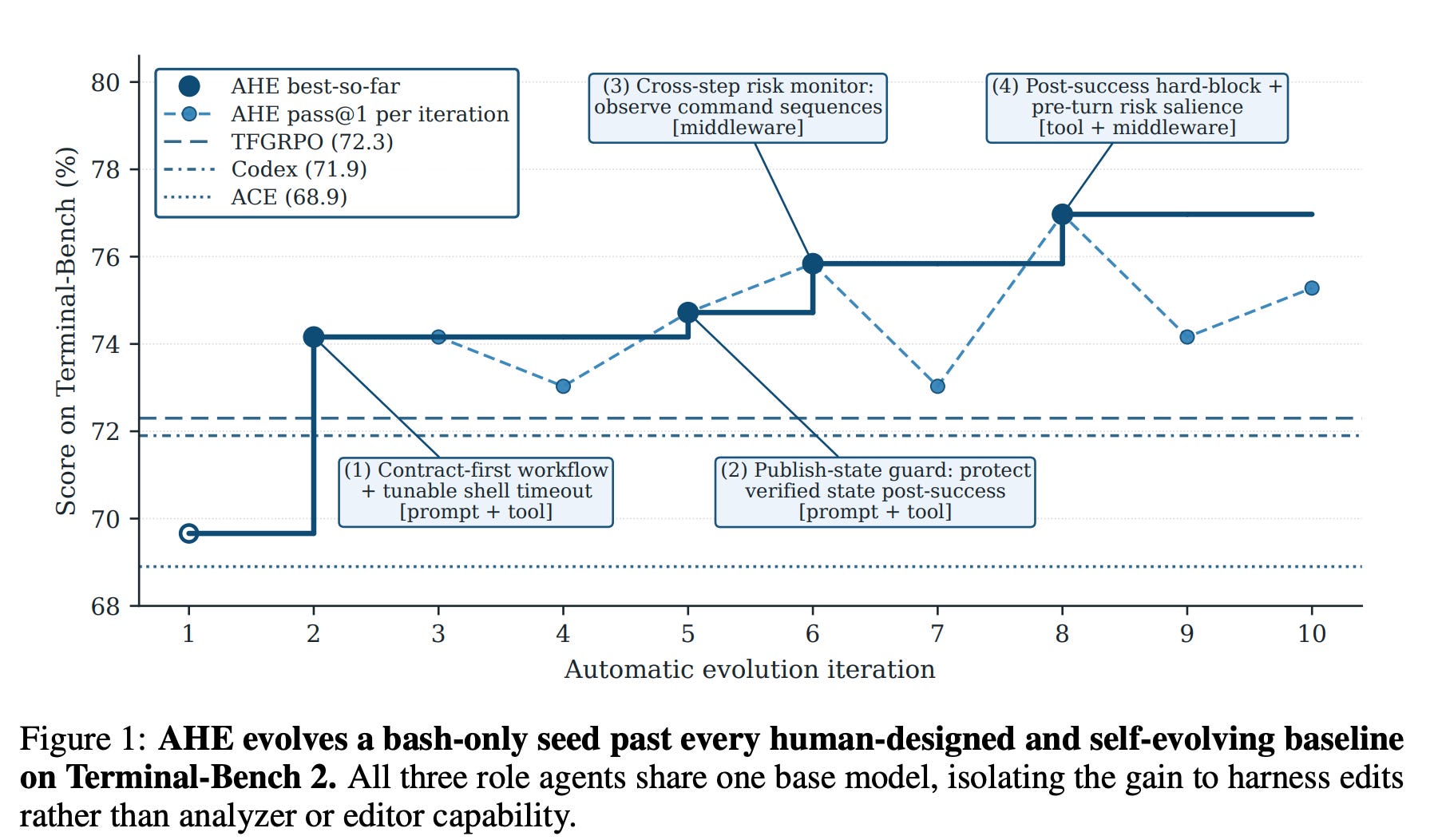
1. Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Jiahang Lin et al. · 2026 · arXiv:2604.25850 · Harness Design
Observability-driven automatic evolution of coding-agent harnesses lifts Terminal-Bench 2 pass@1 from 69.7 to 77.0 over 10 iterations, with transfer across model families. Treats the harness (runtime around a coding agent: tools, prompts, memory, controls) as a first-class engineered artifact and automates its evolution via an observability-driven loop with three pillars — component, experience, decision.
The harness is the unit of optimization. Performance gains come from patching the harness (tools, prompts, controls) — not from retraining the model.
Three observability pillars make evolution diagnostic instead of trial-and-error:
AHE loop: instrument → execute on benchmark → diagnose failure modes via the three pillars → patch harness components → re-evaluate. Repeat to convergence / iteration budget.
Result on Terminal-Bench 2: 69.7 → 77.0 pass@1 after 10 evolution iterations.
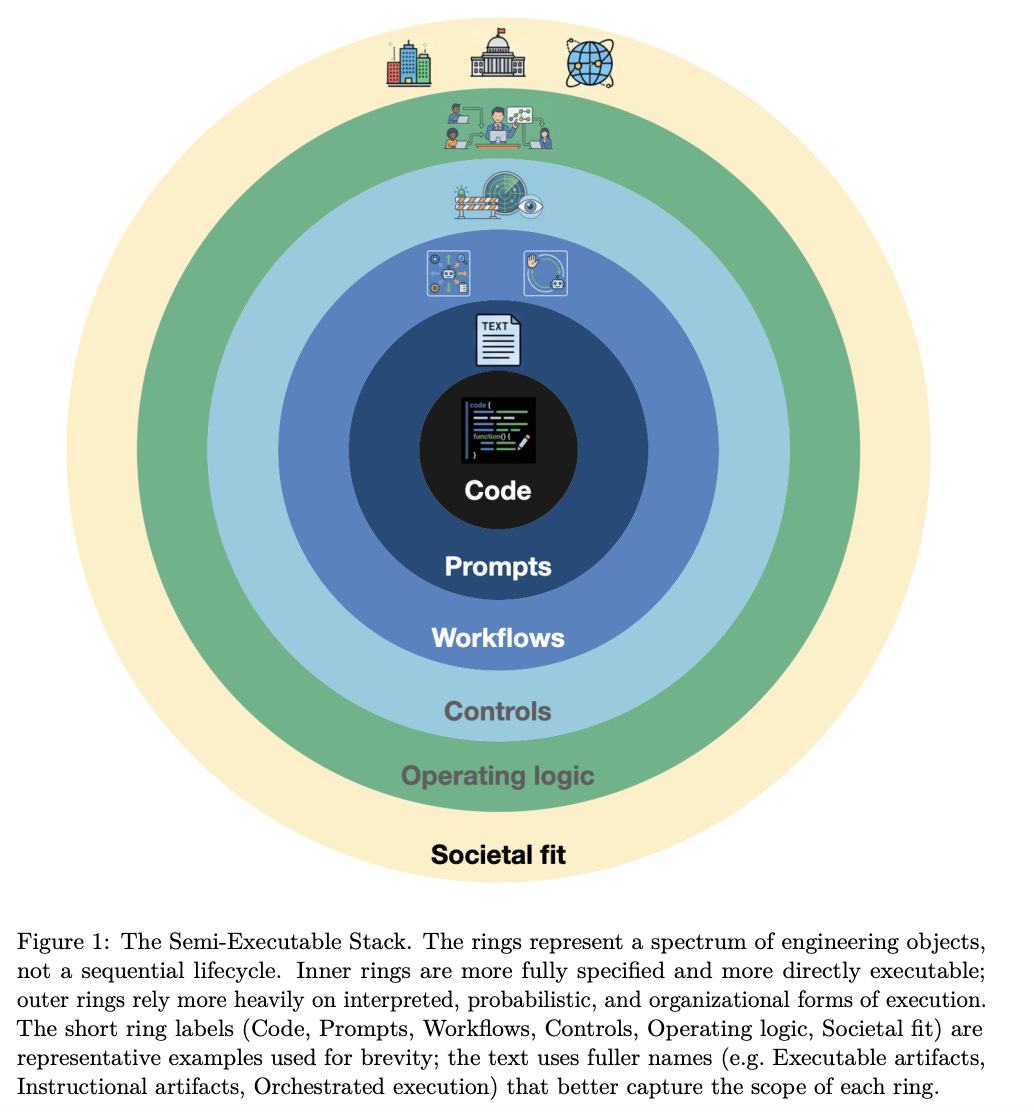
2. The Semi-Executable Stack: Agentic Software Engineering and the Expanding Scope of SE
Robert Feldt et al. · 2026 · arXiv:2604.15468 · Harness Design
Six-ring conceptual reference model spanning intent → spec → code → test as a continuous semi-executable artifact ladder; locates where harness layers live. Conceptual keynote companion (arXiv:2604.15468, submitted 16 Apr 2026) arguing SE isn’t being replaced by LLM agents — the thing being engineered is expanding beyond executable code to semi-executable artifacts: natural language, tools, workflows, control mechanisms, and organizational routines enacted by human or probabilistic interpretation rather than deterministic execution.
The AI threat narrative (”LLMs eat SE”) misreads the situation. The hard-won expertise isn’t losing value; the engineering surface is expanding.
Semi-executable artifacts — natural language specs, tool configs, workflows, controls, organizational routines — now require engineering discipline even though they’re not deterministically executable.
The Semi-Executable Stack spans six rings: executable artifacts → instructional artifacts → orchestrated execution → controls → operating logic → societal and institutional fit.
Contributions, bottlenecks, and transitions can be located on the stack; each ring has neighbors it depends on.
3. HARBOR: Automated Harness Optimization
Biswa Sengupta et al. · 2026 · arXiv:2604.20938 · Harness Design
Bounded bayesian-optimization of fixed-component harness configurations; complement to AHE’s open-ended observability-driven evolution. A formalization of harness configuration as a constrained noisy Bayesian optimization problem over a mixed-variable, cost-heterogeneous flag space, plus a reference solver — HARBOR (Harness Axis-aligned Regularized Bayesian Optimization Routine) — built from a block-additive SAAS surrogate, multi-fidelity cost-aware acquisition, and TuRBO trust regions.
Harness dominates the agent’s operational complexity, not the model. This is the load-bearing assertion — restated: in production agents, the model is one moving part; the harness is the surrounding 80%+ (compaction, caching, memory, trajectory reuse, speculative tools, sandbox glue).
Manual flag stacking doesn’t scale past a handful of bits. Once the harness has more than ~6-8 binary flags (let alone continuous params), the combinatorial space exceeds what humans can grid-search by inspection. This is the practical motivation for automation.
Constrained noisy Bayesian optimization is the right frame. Mixed-variable (binary + categorical + continuous), cost-heterogeneous (some flag combinations cost more inference dollars), and noisy (eval reward is stochastic). They formalize:
Solver components: block-additive SAAS (Sparsity-Aware Sampling) surrogate for high-dim flag space; multi-fidelity cost-aware acquisition function; TuRBO trust-region restarts for non-convex landscape.

4. Workspace-Bench 1.0: Benchmarking AI Agents on Workspace Tasks with Large-Scale File Dependencies
Zirui Tang et al. · 2026 · arXiv:2605.03596 · Eval Substrate
Workspace-Bench 1.0 (388 tasks, 5 worker profiles, 20K files up to 20GB, 7K rubrics) shifts the eval axis from task completion to workspace mastery. Introduces Workspace-Bench, a benchmark for evaluating AI agents on tasks that require reasoning over large-scale, real-world file dependencies — the kind of cross-file retrieval, contextual reasoning, and adaptive decision-making a knowledge worker actually does.
Workspace learning is underexplored. Prior agent benchmarks evaluate on pre-specified or synthesized files with shallow dependency structure; they don’t probe an agent’s ability to reason across a realistic worker’s filesystem.
Scale of realism: 5 worker profiles, 74 file types, 20,476 files (up to 20 GB), 388 tasks, each with its own explicit file-dependency graph and a rubric set (7,399 total) covering cross-file retrieval, contextual reasoning, adaptive decision-making.
Workspace-Bench-Lite = 100-task subset that preserves the distribution while reducing evaluation cost ~70% — a deliberate cost-control move that mirrors a recurring pattern across modern agent benchmarks.
Empirical gap: 4 popular agent harnesses × 7 foundation models. Best 68.7%, average 47.4%, human 80.7% — large headroom; agents fail on long-range cross-file reasoning rather than on individual operations.
5. Autonomous Evolution of EDA Tools: Multi-Agent Self-Evolved ABC
Cunxi Yu et al. · 2026 · arXiv:2604.15082 · Repo Codegen
Self-evolved logic-synthesis on million-line EDA codebases via correctness-gated outer loop; same skeleton as AHE applied to the target codebase rather than the harness. LLM agents autonomously rewrite the source code of ABC — the canonical open-source logic synthesis system — at full million-line integrated-codebase scale, and discover synthesis strategies that exceed human-designed heuristics on the standard EDA benchmark suites (ISCAS 85/89/99, VTR, EPFL, IWLS 2005).
Million-line integrated-codebase scale. Agents reason about cross-file changes that compile and stay correct in a 20-year-old, performance-critical C codebase — not isolated functions like most LLM-code papers.
Discovery, not implementation. The claim is that LLMs discover synthesis optimizations the human community didn’t write, not that they implement known optimizations faster. If defensible with concrete QoR deltas, one of the cleaner claims of LLM-driven scientific advance in a domain with mature priors.
Programming guidance prompts. Meta-instructions about how to structure changes — encoded domain knowledge about synthesis software architecture. The mechanism that prevents random code mutation. Also the piece most likely to be hand-crafted in disguise.
Correctness-gated evolution loop. Compile → validate correctness → score QoR on benchmarks → feedback → next iteration. Correctness is a hard gate; QoR is the optimization signal.
6. SWE-chat: Coding Agent Interactions From Real Users in the Wild
Joachim Baumann et al. · 2026 · arXiv:2604.20779 · Eval Substrate
SWE-Chat assembles a dataset of agent-user interactions during coding tasks; treated as dataset-existence citation per map’s wildcard slot. A 6,000-session, 63k-prompt, 355k-tool-call dataset of real coding-agent interactions collected from open-source developers in the wild — the first large-scale dataset of this kind.
First large-scale wild dataset of coding-agent sessions. 6,000 sessions / 63k prompts / 355k tool calls; the scale is the contribution. Living/auto-updating pipeline is positioned as ongoing infrastructure.
Bimodal usage: 41% vibe-coding (agent writes ~all committed code) + 23% human-only + ~36% mixed. The bimodality itself is the finding — implies there are two distinct user populations (or two distinct task modes), not a continuum of human-AI collaboration.
44% commit survival rate. Of all code an agent produces, less than half ends up in user commits. The remaining 56% is rejected, replaced, or modified beyond recognition.
Agent code has more security vulnerabilities than human code in this dataset. The abstract asserts this but doesn’t quantify; presumably measured via static analyzers on committed code.
7. Insights into Security-Related AI-Generated Pull Requests
Md Fazle Rabbi et al. · 2026 · arXiv:2604.19965 · Empirical PR Studies
Empirical study of 33k+ AI-generated PRs / 675 security-related; merged-but-flawed PRs are load-bearing for agent-PR governance arguments. A descriptive empirical study of 33,000+ AI-generated pull requests filtered to 675 security-related submissions from agentic AI coders.
AI security PRs concentrate on a small set of recurring weakness classes: regex inefficiencies, injection flaws (SQL/cmd/template), path traversal. The “small set” framing matters: it suggests AI security contributions are narrow — addressing easy-to-pattern-match vulnerability classes rather than deep architectural security issues.
Many flawed AI PRs still get merged. This is the load-bearing finding for AIEE. Code review is not catching all the issues — review-as-gate is leaky for AI-generated security work.
Rejection drivers are social/process, not technical. Inactivity (PR sits, no maintainer responds), missing test coverage (a process gate), and similar non-code factors dominate rejection reasons. Technical merit of the security fix often isn’t even the primary axis of decision.
Commit-message quality decoupled from acceptance latency. Prior literature on human PRs shows commit message quality predicts acceptance speed; for AI PRs this signal weakens substantially. Possible interpretations: (a) AI commit messages are uniformly fluent so the signal saturates; (b) reviewers discount commit messages they suspect are LLM-generated; (c) the variance in AI commit quality is too low to discriminate.
What I’m watching for next pulse
Does a unifying behavioral-alignment control primitive land? (the “AHE for behavior” gap)
Do any of the multi-agent-orchestration patterns (SGAgent, RepoReviewer, AgentForge) get reframed as instances of Anthropic’s Planner/Generator/Evaluator pattern, or do they propose distinct architectures?
Do new SWE-bench-successor benchmarks land, or does the wave cool? (signals whether eval-substrate is now over-served)
Does cost-efficiency thicken? Currently a 1-source thread; a single new paper changes its shape considerably.
Behavioral-alignment depth zoom via
/notebook-autoresearch behavioral-alignment-in-coding-agents— should run before the next pulse so the field-pulse can render the depth-pass output (synthesis + new sources) alongside the bootstrap.