
Production AI systems: A reality check
Part 1: Engineering reliable systems on non-deterministic foundations

📌 TL;DR: Production AI requires different engineering patterns than traditional software. This article explains the three-layer AI stack, why research prototypes fail in production, and provides a practical framework for building reliable AI systems using engineering-first principles. You'll learn essential patterns for handling non-deterministic components and get a concrete playbook to start building today.
A senior engineer joins an AI team expecting to work on cutting-edge model architectures. Three months later, they're debugging data pipelines at 2 AM, frantically optimizing API costs that somehow exceeded the monthly AWS bill, and wrestling with tests that pass locally but fail in CI. The reason? The LLM decided to be slightly more verbose today.
This isn't a failure story. It's the reality of AI engineering at the application layer, where the theoretical elegance of foundation models meets the messy complexity of production systems. You're not training the next GPT-5. You're not optimizing CUDA kernels. You're building the critical bridge between breakthrough AI capabilities and actual business value, and it turns out that bridge needs more engineering than anyone warned you about.
The gap between "my RAG demo works" and "our AI system serves 10,000 users reliably" isn't about better prompts or fancier models. It's about understanding where you sit in the AI stack and building with the right patterns from day one.
This article is part of the series:
Part 1: This article.
Part 3.0: Production AI Systems: The Unit Testing Paradox.
Part 3.1: Deterministically Testing Agentic Systems - Coming next week
The Three-Layer AI Stack
The modern AI ecosystem isn't a flat landscape—it's a carefully structured pyramid that Chip Huyen brilliantly articulated in her framework. Understanding this structure isn't academic; it fundamentally shapes how you approach building AI applications.
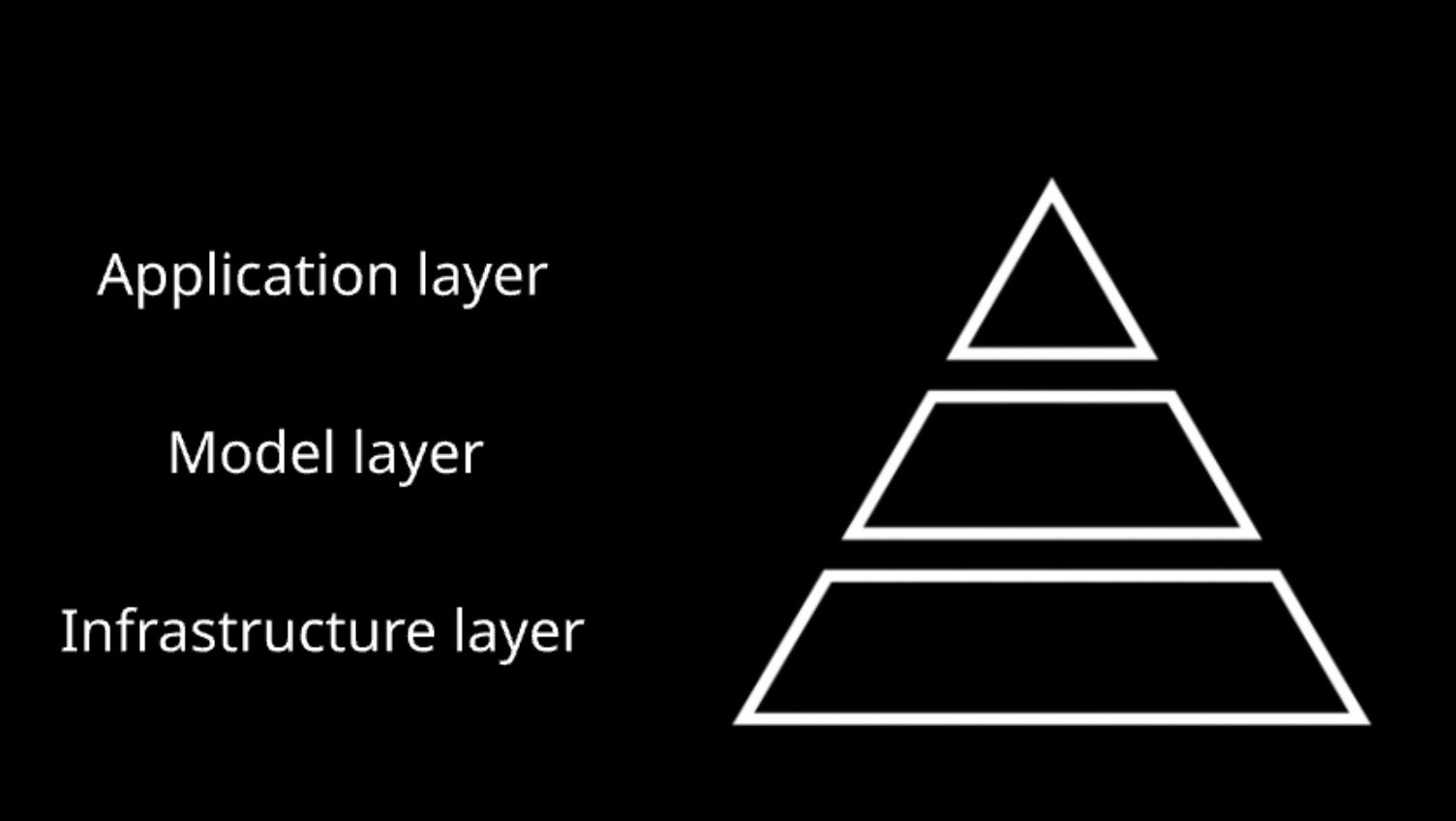
At the infrastructure layer, companies like NVIDIA, AWS, and Google Cloud provide the raw compute power. This is the domain of GPU clusters, distributed training frameworks, and petabyte-scale data pipelines. Unless you're at a hyperscaler or a foundation model company, you're consuming this layer, not building it. The key insight? You inherit both its capabilities and constraints—latency bounds, rate limits, regional availability, and yes, those eye-watering compute costs.
The model layer sits in the middle, where OpenAI, Anthropic, Google, and others train foundation models. These teams wrestle with transformer architectures, constitutional AI, and reinforcement learning from human feedback. They're pushing the boundaries of what's possible with language understanding and generation. As an application developer, these models are your primary building blocks—powerful, but opaque. You can fine-tune them, prompt them, even chain them together, but their core behaviors remain largely fixed.
Then there's the application layer, your domain. This is where abstract AI capabilities become concrete business solutions. It's where a language model becomes a customer service agent, a code reviewer, or a medical diagnostic assistant. Industry reports show that 67% of enterprises are building at this layer, up from just 23% two years ago. The explosion isn't just in quantity; it's in complexity.
Here's what makes this layer uniquely challenging: you're orchestrating services you don't control, with behaviors you can't fully predict, at costs that scale with every user interaction. A traditional web service might handle a million requests for pennies. Your AI service might spend $10 on those same requests, and that's before considering the cascade effects of retries on failures, context window management, and multi-step reasoning chains.
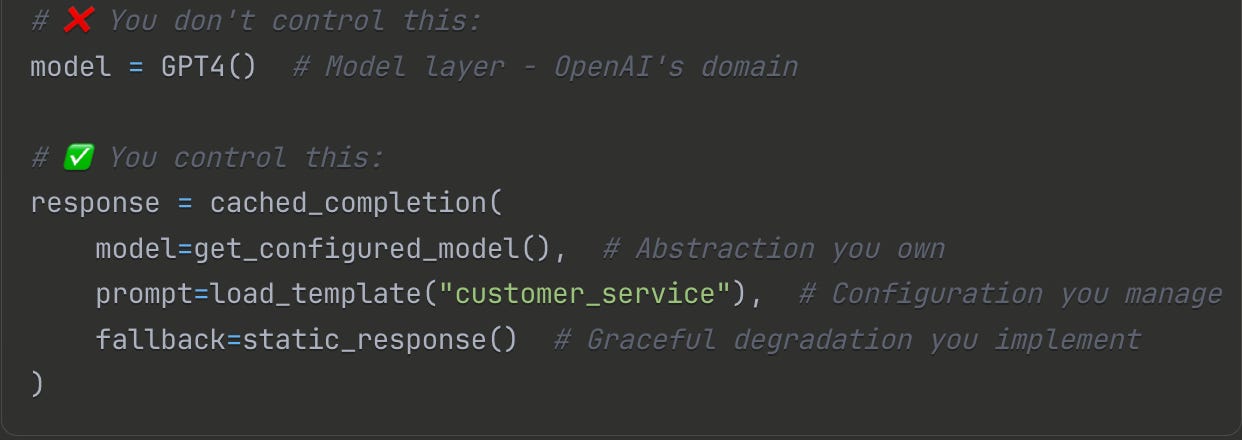
Your position in this ecosystem matters because it defines your constraints and opportunities. You can't make the model inherently smarter (that's the model layer's job), and you can't make GPUs cheaper (that's infrastructure). But you can build resilient systems that gracefully handle model uncertainties. You can create testing strategies that catch issues before they reach production. You can architect data pipelines that minimize API calls while maximizing relevance. Most importantly, you can establish patterns that make AI applications as reliable and maintainable as any other production system.
The Production Reality Check
The most dangerous moment in any AI project? When the prototype works perfectly.
A data scientist builds a RAG system in a Jupyter notebook. It retrieves accurately, responds coherently, and everyone's impressed. Six months later, that same system is hemorrhaging money in production, failing mysteriously, and requiring constant manual intervention. The notebook never had to handle concurrent users competing for vector database connections, documents exceeding context windows, or the same question getting different answers five minutes apart. Shankar et al. documented this exact phenomenon in their study on how ML systems behave unpredictably until they hit production.
Research optimizes for possibility. Engineering optimizes for reliability.
This fundamental difference shapes everything about how we build AI systems. A research prototype might tolerate a 15% failure rate if the successes are spectacular. A production system serving customers needs 99.9% uptime, predictable costs, and graceful degradation when things go wrong.
The hidden iceberg of production AI reveals itself through a cascade of requirements:
• Malformed responses: Your LLM returns invalid JSON despite perfect prompts
• Service failures: Embedding services timeout during peak hours (>30s latency spikes)
• Cost explosions: That multi-agent system makes 47 API calls at $0.03 each = $1.41 per interaction
• Compliance requirements: Audit trails, PII scrubbing, response filtering for data protection
• Engineering wrapper: Connection pooling, exponential backoff, caching, request queuing
• Observability needs: Cost tracking per department, performance metrics, error rates
The 90/10 rule applies brutally: 10% of your code handles the actual AI logic, while 90% handles everything else. As Google's MLOps guidelines emphasize: "The real challenge isn't building an ML model, the challenge is building an integrated ML system and to continuously operate it in production."
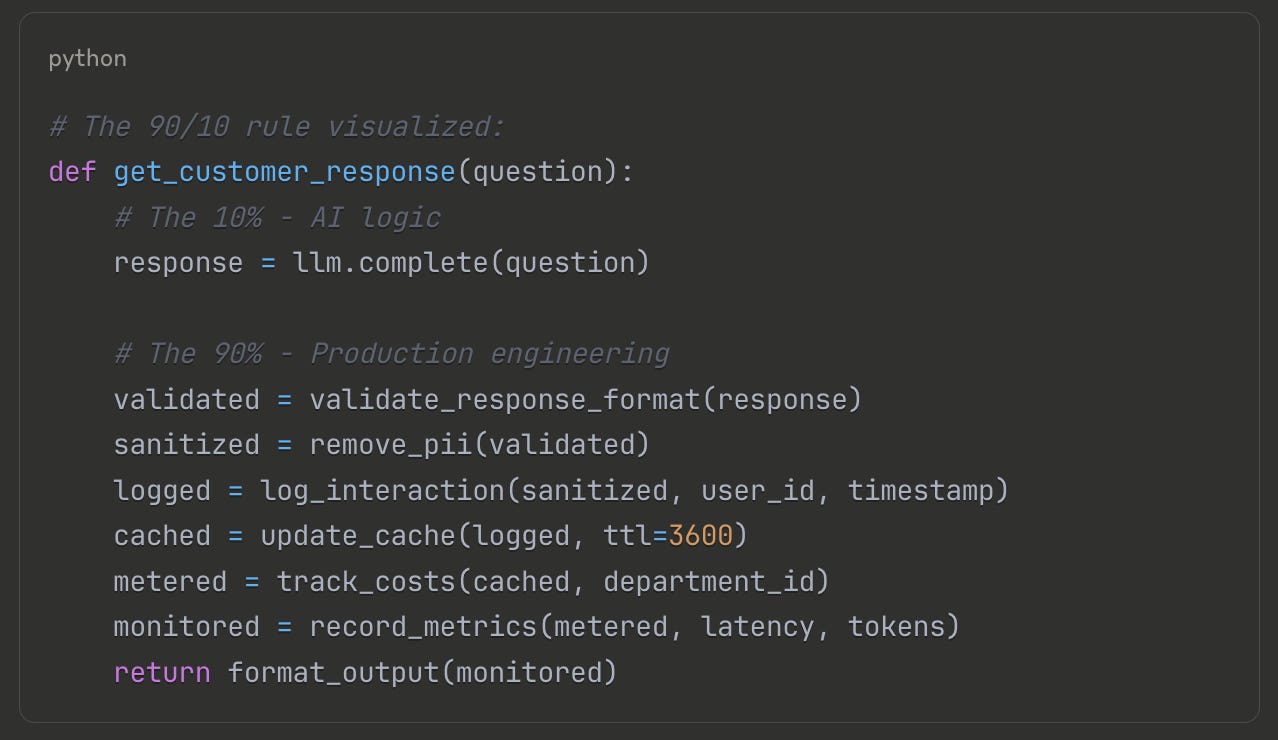
Moving from a RAG demo to production meant adding connection pooling for vector database access, implementing exponential backoff for API retries, building a caching layer for embeddings, adding cost tracking per department, creating fallback responses for service outages, implementing request queuing for rate limit management, and building comprehensive observability across all components. The core RAG logic? Unchanged. The engineering around it? 10,000 lines of production code versus 50 lines of AI logic.
💡 Production Reality: The $72,000 Weekend
A team deployed their RAG system without retry limits. A bug caused infinite retries on failures. Each retry called GPT-4 with full context (8K tokens). The weekend bill: $72,000. The fix: Three lines of code for exponential backoff with max retries. The lesson: Production AI needs defensive engineering.
But here's what makes the application layer uniquely challenging: you're building deterministic systems on probabilistic foundations you don't control. Model providers update their systems without announcement, and your carefully crafted prompts suddenly return different schemas. Previously reliable workflows break when models become more or less verbose overnight. The same prompt to the same model yields different responses based on load balancing, temperature settings, or just inherent randomness in token sampling. You discover this when production starts failing in subtle ways your tests don't catch. As researchers at Carnegie Mellon's SEI note, these bugs are "rare, intermittent, and hard to reproduce"—the worst kind in production.
The cost structure breaks every assumption about system scaling. Traditional systems have marginal costs approaching zero. With AI applications, costs scale linearly with usage, and not gently. One team celebrated hitting 10,000 daily active users until they realized they were spending $3,000 per day on API calls. The math was simple: 10,000 users × 5 interactions × $0.06 per interaction. The solution required redesigning their entire interaction pattern.
The cruel irony? These challenges intensify as you succeed. More users mean more edge cases. Higher stakes mean stronger reliability requirements. Broader deployment means more diverse failure modes. The prototype that handled 100 friendly beta testers crumbles under 10,000 real users who paste entire novels into your carefully token-limited input fields. Google's seminal paper on ML technical debt warned us in 2015, but with foundation models, you're not just maintaining code; you're maintaining compatibility with constantly evolving external services you'll never control.
Building on Solid Foundations
After staring into the abyss of production complexity, here's the good news: you don't have to solve these problems from scratch. The chaos becomes manageable when you start with the right foundation.
Most AI projects begin backwards. A developer gets API access, writes some prompt experiments in a notebook, then tries to retrofit production practices later. Six months in, they're refactoring everything because the original structure can't support testing, deployment, or monitoring. The technical debt isn't just high interest; it's compounding daily.
The ai-base-template flips this sequence. Before you write a single prompt or make any API calls, you establish engineering discipline:
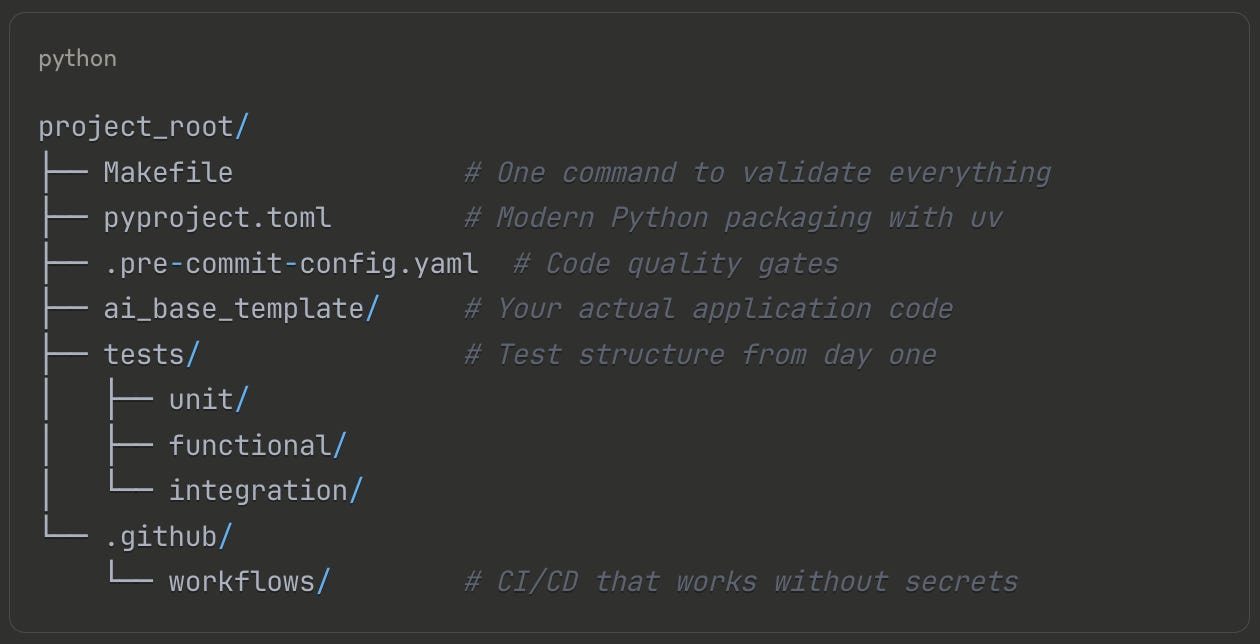
This structure solves the fundamental problem: AI projects need more engineering rigor, not less. The Makefile isn't just convenience; it's consistency. Every developer runs make validate-branch and gets the same formatting, linting, and test execution. No more "but it worked on my machine" when Ruff formatted differently on your colleague's setup.
Modern Python packaging through uv changes everything. Traditional pip and requirements.txt lead to dependency hell, especially with the rapidly evolving AI ecosystem. The pyproject.toml locks your dependencies precisely. When OpenAI releases a breaking change to their client library, your production environment stays stable. When you need to upgrade, it's a controlled, testable change, not a surprise at 3 AM.
The test markers might seem premature when you haven't written any AI code yet, but they establish the right habits:
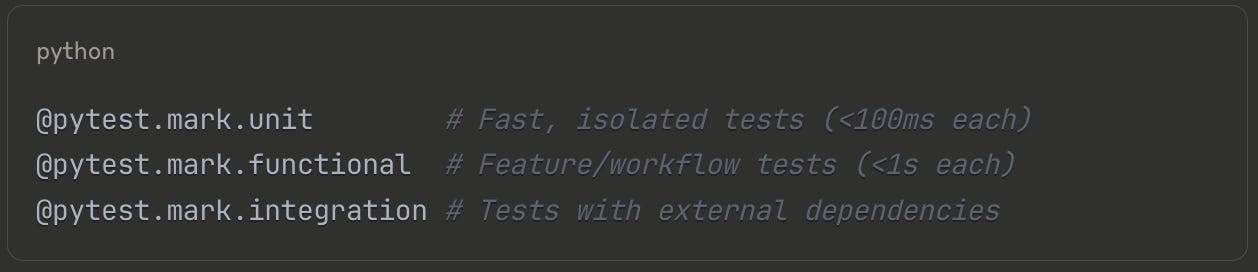
You run make test-unit hundreds of times a day during development. These tests must be fast and deterministic. Functional tests validate complete workflows. Integration tests verify external connections. This separation becomes crucial when you add AI components. Your prompt parsing logic gets unit tests. Your RAG pipeline gets functional tests. Your API calls get integration tests that can be skipped in CI to save costs.
The pre-commit hooks enforce quality before code even reaches version control. Ruff formats your code. MyPy checks your types. The hooks catch the embarrassing mistakes before they become pull request comments. This matters more for AI code, where a missing type hint might mean you're passing a string to something expecting a list, causing mysterious failures three function calls deep.
GitHub Actions workflows complete the safety net. They run on every push, every pull request, without needing API keys or secrets. How? Because you've structured your code to be testable without external dependencies. The workflows validate formatting, run linting, execute tests, and ensure type safety. Your AI logic will plug into this existing infrastructure, inheriting all these quality gates automatically.
The template includes everything you need to start building immediately:
• 🐍 Python 3.12 with modern packaging via uv
• 🧪 Testing setup with pytest (unit, functional, integration markers)
• 🔧 Code quality with Ruff (formatting + linting) and MyPy (type checking)
• 📝 Type hints and Pydantic for data validation
• ⚡ Make commands for common development tasks
• 📓 Jupyter support for experimentation
• 🎯 Pre-commit hooks for quality gates
• 📦 ML-ready structure (just uncomment libraries in pyproject.toml)
The real power comes from cognitive load management. When every project starts the same way, when every developer knows where to find configurations, tests, and utilities, your team's mental energy focuses on solving AI problems rather than debating project structure. The boring decisions are made, documented, and automated.
This isn't about following arbitrary rules. Every aspect of ai-base-template exists because someone learned an expensive lesson. The Makefile exists because manual command sequences lead to skipped steps. The uv packaging exists because pip conflicts wasted days of debugging. The test structure exists because retrofitting tests onto unstructured code is nearly impossible.
Starting here means you're building on bedrock, not sand. Your AI components will slot into a proven structure. Your team will follow established patterns. Your production deployments will inherit battle-tested practices. Most importantly, when things go wrong (and they will), you'll have the observability, testing, and structure to fix them quickly.
Engineering for Uncertainty
With solid engineering foundations in place, you face a deeper challenge: how do you engineer systems when the core components behave probabilistically? Traditional software engineering assumes predictable components. Service A calls Service B and gets a deterministic response. AI applications shatter this assumption at every level.
The shift requires new architectural patterns, not because they're trendy, but because they're necessary for survival. These patterns aren't suggestions; they're requirements discovered through painful production experiences.
Configurability becomes critical when you realize hardcoded prompts are ticking time bombs. The prompt that works perfectly with GPT-4 today might produce garbage with tomorrow's model update. Your carefully tuned temperature setting becomes obsolete when Claude's behavior changes. Systems that bake these values into code require redeployment for every adjustment. The teams that survive build configuration systems that allow real-time adjustments without code changes. Model selection, prompt templates, temperature settings, retry logic, timeout values, all become runtime configurations.
Observability transforms from nice-to-have to existential necessity. When a traditional service fails, you have stack traces, error codes, and deterministic reproduction steps. When your AI system produces a nonsensical response, you have... what exactly? Without comprehensive logging of prompts, responses, token counts, latencies, and model versions, debugging becomes impossible. You need to know not just what the model said, but why it might have said it. Context windows, token limits, rate limit approaches, all invisible until you instrument them.
Testability seems impossible but becomes mandatory. How do you write unit tests for non-deterministic components? The answer isn't to skip testing; it's to architect for testability from the start. This means abstraction layers that allow mock implementations, interfaces that separate AI logic from API calls, and test harnesses that can validate behavior without requiring deterministic outputs. The team that says "we can't test AI code" is the team that will have a $72,000 weekend.
Abstraction saves you from vendor lock-in disasters. When OpenAI deprecates your model with 30 days notice, or when Anthropic's API goes down during Black Friday, your abstraction layer determines whether you have a migration path or a crisis. Teams that couple directly to provider SDKs learn this lesson expensively.
Graceful degradation keeps you online when AI fails. Because AI will fail. APIs go down. Rate limits hit. Costs spike. Systems architected for uncertainty have fallback paths: cached responses for common queries, simplified logic when the smart model is unavailable, human escalation when confidence is low.
The architecture challenge operates at two levels. At the system level, you're orchestrating services, managing queues, implementing caches, and handling distributed failures. At the unit level, you're managing prompts, parsing responses, handling retries, and validating outputs. Both levels demand equal attention. A perfectly designed microservice architecture means nothing if your prompt parsing fails silently.
📋 Pattern Checklist for Production AI:
✅ Configuration externalized from code
✅ Every AI interaction logged with context
✅ Unit tests that run without API calls
✅ Provider-agnostic interfaces
✅ Fallback paths for every AI component
✅ Cost tracking at interaction level
✅ Response validation and sanitization
The FM App Toolkit embodies these patterns, providing concrete implementations of these architectural principles. The upcoming articles will dive deep into each pattern, showing not just why they matter, but exactly how to implement them. But the principles themselves are universal. Whether you use our toolkit or build your own, these patterns form the foundation of production AI systems.
Getting Started
Theory without action is worthless. Here's your immediate path from reading to building.
Today, right now: Go to the ai-base-template repository and click "Use this template" to create your own repository. Don't overthink it. Don't wait for the perfect project idea. GitHub will create a fresh copy with all the structure ready to go. Run make init in your new repo. The fifteen minutes you invest now save weeks of refactoring later.
This week: Build something real, even if it's small. A prompt validator. A response parser. An embedding cache. The specific functionality matters less than establishing the patterns. Write tests first, even before your AI logic. Create that .env file for configurations. Run make validate-branch obsessively. Feel the rhythm of professional AI development.
Explore early: The FM App Toolkit repository contains battle-tested implementations of every pattern discussed here. Browse the code. See how DocumentRepository abstracts data access. Understand how MockLLMWithChain enables deterministic testing. Watch how SimpleReActAgent makes debugging possible. You don't need to master it all now, but familiarizing yourself with the patterns accelerates your learning.
Coming next: This series continues with deep dives into the critical patterns that make production AI possible. We'll explore data loading strategies that work across environments, testing approaches that catch bugs before they cost money, and architectural patterns that turn chaotic AI interactions into observable, debuggable systems. Each article builds on these foundations, taking you from concept to production-ready implementation.
The mindset shift starts now. You're not building an AI demo that impresses in meetings. You're engineering a system that serves real users, handles real load, and solves real problems. Every production AI system that works reliably follows these patterns. Every failure story stems from ignoring them.
Your AI engineering journey doesn't start with prompts or embeddings or agents. It starts with clicking "Use this template" and running make environment-create.
The future is probabilistic. Your engineering doesn't have to be.
References & Further Reading
Research & Academic Papers
Carnegie Mellon SEI (2024). The Challenges of Testing in a Non-Deterministic World. Analysis of why non-deterministic systems make bugs rare and hard to reproduce.
Google Cloud Architecture (2024). MLOps: Continuous delivery and automation pipelines in machine learning. Comprehensive guide to production ML operations.
Shankar, S., et al. (2024). We Have No Idea How Models will Behave in Production until Production. Study on the experimental nature of ML systems moving from notebooks to production.
Sculley, D., et al. (2015). Hidden Technical Debt in Machine Learning Systems. NeurIPS. The seminal paper introducing ML technical debt concepts.
Books & Industry Insights
Huyen, Chip (2024). AI Engineering. O'Reilly Media. Comprehensive framework for building AI systems.
Huyen, Chip (2023). Building LLM applications for production. Practical insights on production LLM challenges.
Tools & Templates
AI Base Template: Production-ready Python template with modern tooling for AI/ML projects
FM App Toolkit: Battle-tested patterns and implementations for production AI applications
Additional Resources
MLOps Community: Latest practices and challenges in deploying ML systems at scale
Faubel, L., Schmid, K. & Eichelberger, H. (2023). MLOps Challenges in Industry 4.0. SN Computer Science. Analysis of MLOps challenges across industrial contexts.